Joel Shprentz
shprentz@bdm.com
BDM Federal, Inc.
1501 BDM Way, McLean, VA 22102
A group of Python classes model HTML formatted documents and their contents. Mimicking the hierarchical structure of HTML tags, content objects form a treelike representation of an HTML document. A tag factory object creates each node in the tree, typically a tagged element, which may include attributes and initial contents. Additional contents--text and other tags--can be added later. The HtmlDocument class provides an overall structure for HTML documents. Application-specific subclasses override default methods that create the start, body, and end of a document. Often a complete HTML document can be created by instantiating an HtmlDocument subclass with a few parameterized values, such as document title. When a document is completely built, it can be written to any output stream, such as a file, pipe, or socket. Individual tags can also be written to output streams. The HTML classes provide more functionality and greater reusability than the simple Python output statements often used.
A common problem at World Wide Web sites is the automatic creation of HTML documents. Whether the documents are created on the fly by a CGI script or in advance by a batch production system, the most common approach is to execute a sequence of print statements that create the HTML document one line at a time. This strategy works with any programming language. For example, here is a Unix shell script to generate a simple HTML document.
#!/bin/sh
echo '<HTML><HEAD>'
echo '<TITLE>Hello World</TITLE></HEAD>'
echo '<BODY><H1>Hello World</H1>'
echo '<P>Program with'
echo '<A HREF="http://www.python.org/"'
echo '>Python</A> today</BODY></HTML>'
In actual documents, the body is created based on some calculation, model, or information retrieval, often in response to user input. As the complexity of the documents grows, programmers migrate from simple scripting languages to more complex interpreted languages, like TCL and Perl, and then to compiled languages, like C. Object oriented languages are also available: interpreted languages like Python and compiled languages like C++.
The interpreted Python language[1] combines the benefits of object oriented development with the rapid application development environment of interpreted languages. The Python class library[2] contains a rich collection of tools including an HTML parser and a CGI interface, but it does not include any classes for constructing HTML documents. Thus, despite all of Pythons capabilities, the Python program to generate a simple HTML document is almost identical to the shell script:
print '<HTML><HEAD>'
print '<TITLE>Hello World</TITLE></HEAD>'
print '<BODY><H1>Hello World</H1>'
print '<P>Program with'
print '<A HREF="http://www.python.org/"'
print '>Python</A> today</BODY></HTML>'There are several potential problems with this approach:
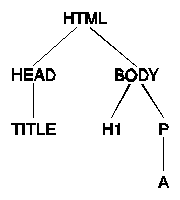
The tagged text elements of HTML[3] documents are organized in a treelike structure, with each tag potentially containing text intermingled with one or more other tags. The tags in the example document have this tree structure:
This tree structured hierarchy is similar to the composite pattern[4] from object oriented design. Following this pattern, an abstract class, HtmlContents, declares common operations, most notably writeHtml, which writes the HTML contents to a file. Subclasses of HtmlContents implement these operations for specific types of HTML document contents: tags, text, and space. Tag objects, called HtmlElement, implement additional methods to modify contents and attributes. Preformatted elements, like the <PRE> tag, are represented by a subclass of HtmlElement. The object structure is shown below in Coad notation[5]:
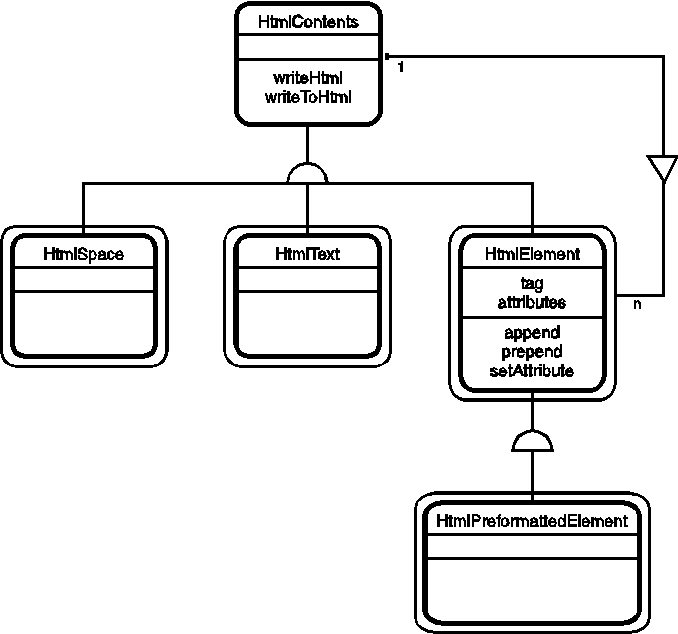
There are many tags in the HTML 2.0 specification, so another class, HtmlTagFactory, defines methods to create a valid HtmlElement object for each possible tag. As HTML evolves, the HtmlTagFactory class can be extended and revised to accommodate new tags. There is only one instance of HtmlTagFactory. It is named Tag.
HtmlElement objects can be created with or without initial contents. The initial contents can be text, HtmlElement objects, or lists. List elements can also be text, HtmlElement objects, or lists. For example,
document = Tag.HTML ()
docTitle = Tag.TITLE ("Sample document")
docHead = Tag.HEAD (docTitle)
docBody = Tag.BODY ([Tag.P ("Some text), Tag.P ("More text")])The same text, HtmlElement objects, and lists can be appended or prepended to any HtmlElement objects. For example, to complete the sample document,
document.append ([docHead, docBody])
This capability is often used within a loop to construct a list. For example, this code constructs an ordered list of words:
words = ["red", "yellow", "green", "blue", "orange"]
wordList = Tag.OL ()
for word in words:
wordList.append (Tag.LI (word))Many HTML tags have attributes. These can be specified when the HtmlElement object is created or set later. An anchor tag with an HREF attribute would look like this:
Tag.A ("click here", "http://www.python.org/")Forms and form fields are other types of HTML tags. As HTML is defined, there are many variations of INPUT tag (text, check boxes, etc.). Each variation of the INPUT tag is implemented by a different subclass of HtmlElement. The tag factory understands all of these forms. For example, to create a text field to hold a 5-digit zipcode with no default value,
Tag.inputText (None, "zipcode", 5, 5)
Form field objects have a unique capability: When the value dictionary returned by Python's CGI class is passed to a tag tree, each form field in the tree will lookup its value in that dictionary and use the value when generating the HTML document. This makes it easy to preset a form based on a user's responses.
All subclasses of HtmlContents respond to the writeHtml method by writing their HTML representation to a specified file. The sample document created above could be written to standard output as follows:
from sys import stdout
document.writeHtml (stdout)
The various tag objects support nonsequential construction of HTML documents. This is essential when related information is distributed throughout a document. For example, a table of contents at the beginning of the document should list only the sections actually included in that document. The "print a statement at a time" strategy cannot easily create such documents. Consider this pseudocode for a document:
print heading
print table of contents
if condition 1 then print section 1
if condition 2 then print section 2
print footing
When the table of contents is being printed, this code has not yet evaluated the conditions nor decided which sections to include. The conditions are often of the form, "did the query return any results," so it is inconvenient to evaluate them except when printing the section based on the query results. A possible solution is to first print the sections to a temporary file and then merge that file into the final file.
Tag objects offer a better solution. The tag hierarchy need not be created sequentially, but can be augmented as needed. The sectioned document can be created with this pseudocode:
body = Tag.BODY ()
body.append (heading)
toc = table of contents
body.append (toc)
if condition 1 then
toc.append ("Section 1")
body.append (Section 1)
if condition 2 then
toc.append ("Section 2")
body.append (Section 2)
body.append (footing)
Each section adds its own entry to the table of contents, which is already correctly positioned in the document. Similar techniques can be used to place summary information near the front of a document (e. g., average values or counts of search results).
This technique for document construction is possible because today's computer memories are guaranteed to be large enough to hold the tree representation of an HTML document. It is more effective to manipulate the entire document in memory then to repeatedly process and output small amounts of information.
The HTML output includes all tags and attributes, replaces special characters (e.g., &) with their HTML representation, suppresses redundant spaces, breaks text into lines of about 70 characters, and adds line breaks after major tags (e.g., H1 and P). Some of these steps require tracking the capacity and spacing status of each output line, a capability not present in Python's file class. Although the tracking features could be implemented by subclassing the file class, this would preclude using sockets and other file-like objects.
The implementation chosen relies on HtmlFile, a wrapper class for Python files. HtmlFile tracks spacing, character count, newlines, and preformatted text for a given file. The two principal public methods are write (for text) and writeAsIs (for tags and attribute values). HtmlFile makes the implementation of writeHtml trivial in the HtmlContents class:
def writeHtml (self, outfile)
self.writeToHtml (HtmlFile (outfile))Each subclass of HtmlContents must implement writeToHtml. The HtmlText objects convert special characters before writing the text:
def writeToHtml (self, outfile)
pieces = splitfields (self.text, "&")
outText = joinfields (pieces, "&")
. . .
outfile.write (outText)The HtmlElement objects must write a starting tag, which might include attributes; the contents, which are found on a list containing text and other elements; an optional ending tag; and an optional line break. Here is the definition:
def writeToHtml (self, outfile)
self.writeStartTag (outfile)
self.writeContents (outfile)
if self.needEndTag:
outfile.write ("</%s>" % self.tag)
if self.tagEndsLine:
outfile.writeNewline ()
A typical web application will contain several types of pages, each produced by a different program. Examples include query forms, result pages, and indices. Graphic designers[6] recommend that these pages share common design elements, such as logos, banners, feedback links, modification date, and navigation aids. These common elements typically appear at the top and bottom of each page.
An abstract class, HtmlDocument, provides a framework for implementing documents with common design elements. HtmlDocument is similar to HtmlElement in that it responds to append and prepend methods to add elements to the document body. It also responds to writeHtml to write to a file and printHtml to write to standard output. However, when implementing writeHtml, HtmlDocument will call three methods to create common design elements: head, startBody, and endBody.
A web application will implement head, startBody, and endBody in a subclass of HtmlDocument.
class SampleHtmlDocument (HtmlDocument):
Consider a page design for a typical application. At the top of each page, there is a banner logo, then a title and subtitle. The SampleHtmlDocument startBody method could look like this:
def startBody (self):
return [self.banner (), self.pageTitles ()]The two methods used to construct the list must also be defined. This method builds the page titles.
def pageTitles (self):
titles = []
if self.title:
titles.append (Tag.H1 (self.title))
if self.subtitle:
titles.append (Tag.H2 (self.subtitle))
titles.append (Tag.HR ())
return titlesOnce the basic page design is established for an application, other subclasses can add additional design elements required by particular page types, such as query forms.
There are some advantages to this approach:
The code and design described have been used on several recent internal projects. Earlier projects were implemented with the sequential print method described in the introduction.
The first improvement noticed was that the HTML produced is correct. There were no missing tags or improperly nested elements. These errors are now unlikely to occur because the document structure is reflected in the Python code and because the HTML output is generated by well tested code.
Sharing a common page design among several applications has been a great benefit. With the print statement method, a design change required modifications to each program that produced a different type of page. With the object-oriented approach, only one file needs to be changed.
Programmers no longer work at the raw HTML level. Instead, they treat HTML document bodies as trees of tags. These HTML element, tag, and document classes match the level of abstraction provided by many other classes in the Python library.