Presented at PyCON March 24, 2004 in Washington, DC by Jim Hugunin
IronPython is a new implementation of the Python language targeting the Common Language Runtime (CLR). It compiles python programs into bytecode (IL) that will run on either Microsoft's .NET or the Open Source Mono platform. IronPython includes an interactive interpreter and transparent on-the-fly compilation of source files just like standard Python. In addition, IronPython supports static compilation of Python code to produce static executables (.exe's) that can be run directly or static libraries (.dll's) that can be called from other CLR languages.
The CLR is designed to be a target platform for multiple programming languages and to provide a common type system that can enable these languages to seamlessly interoperate with each other. IronPython adds Python to this mix of languages allowing Python code to easily use and be used from the wide variety of other languages that support the CLR.
This paper describes IronPython-0.2, a research prototype implementing the full semantics of the Python language. Before IronPython can be used as a real development platform it still needs considerable testing, packaging and library development. More information on IronPython can be found at http://ironpython.com.
Previous attempts to implement Python and other highly dynamic languages for the CLR have resulted in systems with extremely poor performance. Performance so bad that they were considered unusable.
"The speed of the current system is so low as to render the current implementation useless for anything beyond demonstration purposes.“ – ActiveState’s report on Python for .NET
"The CLI is, by design, not friendly to dynamic languages. Prototypes were built, but ran way too slowly."– InfoWorld, Aug. 2003
There are many other such anecdotal remarks on the web claiming that the CLR is a poor platform for dynamic languages. These results were surprising to me. The CLR is supposed to be a superset of the functionality in a JVM. The JVM can host a number of dynamic languages with very good performance. Jython stands as the clearest proof of this with performance close to the native C implementation of Python (CPython). I wanted to pinpoint the fatal flaw in the design of the CLR that made it so bad at implementing dynamic languages. My plan was to write a short pithy article called, "Why .NET is a terrible platform for dynamic languages".
Unfortunately, as I carried out my experiments I found the CLR to be a surprisingly good target for dynamic languages, or at least for the highly dynamic specific case of Python. This was unfortunate because it meant that instead of writing a short pithy paper I had to build a full Python implementation for this new platform to see if there would be any hidden traps along the way. Because performance is such a dominant question for Python on the CLR, the rest of this paper focuses entirely on performance issues and measurements.
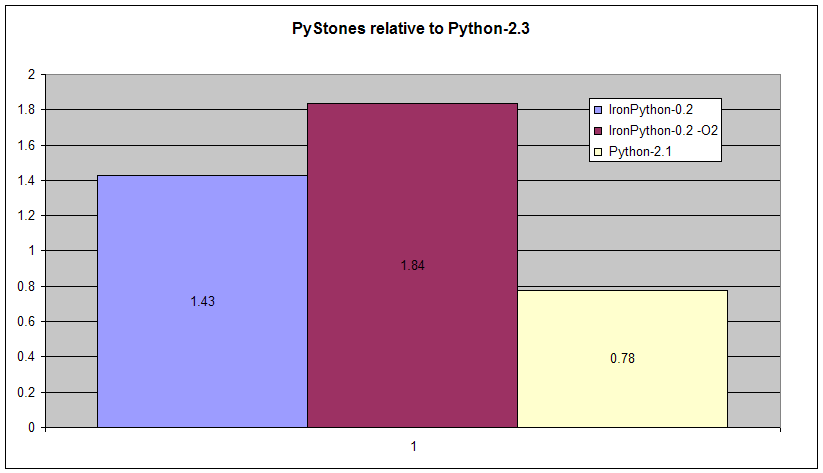
To initially assess the performance of IronPython I've measured its speed on the venerable pystone benchmark. pystone is from the Python-2.3 standard install under Lib/tests/pystone.py. This is the only benchmark that ships with the standard Python distribution and as such has become a de facto standard.
All times were measured on a 1.4GHz Pentium-M processor (a ThinkPad X31 laptop) running at full speed under Windows XP. The following systems were tested:
These numbers show the relative performance of the four systems tested on pystone. Python-2.3 is represented in this and all benchmark results as 1.0 and higher numbers are better.
These initial results show that IronPython is somewhat faster than Python-2.3 on this classic benchmark. This single result is not enough to claim that IronPython is generally faster than Python-2.3. Many more benchmarks across a range of different applications would be needed to do that. However, pystone has proven to be a surprisingly predictive benchmark and this result suggests strongly that Python can run on the CLR with either acceptable or extremely good performance.
Note: IronPython-0.2 implements the full range of dynamic python behavior from locals() and globals() to meta-classes and dynamically adding and removing methods to silent overflow from ints to longs. It is certainly possible to build a pseudo-Python implementation that can run this particular benchmark very quickly indeed if these kinds of dynamic features are ignored.
Micro benchmarks are a valuable tool for understanding the low-level performance tradeoffs of different systems and implementation techniques. However, they are also easy to manipulate and misunderstand. I've made every effort to ensure that these benchmarks accurately reflect the performance of IronPython and the standard Python implementation.
The code for these benchmarks is generated by a script. Each benchmark has the same structure where the test expression is repeated 20 times:
def test(L):
<Initialization>
for i in range(L):
<Test>; <Test>; ... <Test>;
Here's one concrete example:
def test(L):
gd = globals()
for i in range(L):
gd['gx'] = i; gd['gx'] = i; gd['gx'] = i; gd['gx'] = i; gd['gx'] = i;
gd['gx'] = i; gd['gx'] = i; gd['gx'] = i; gd['gx'] = i; gd['gx'] = i;
gd['gx'] = i; gd['gx'] = i; gd['gx'] = i; gd['gx'] = i; gd['gx'] = i;
gd['gx'] = i; gd['gx'] = i; gd['gx'] = i; gd['gx'] = i; gd['gx'] = i;
You can see from this example just how easy it might be for a compiler to optimize this micro benchmark so that the results are meaningless. These micro benchmark results are only meaningful because none of the Python implementations being tested in this section perform that kind of aggressive optimization.
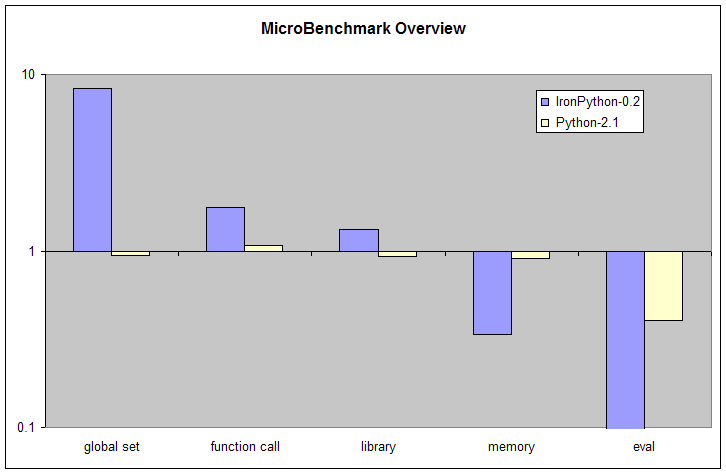
The overview shows a range of performance where IronPython goes from 10x faster than Python-2.3 for setting the value of a global variable to 10x slower for evaluating a small piece of code provided as a string. In the middle sit tests where most of the time is spent in library code either written in C# for IronPython or in C for Python-2.3. We'll now look at each of these 5 categories in more detail.
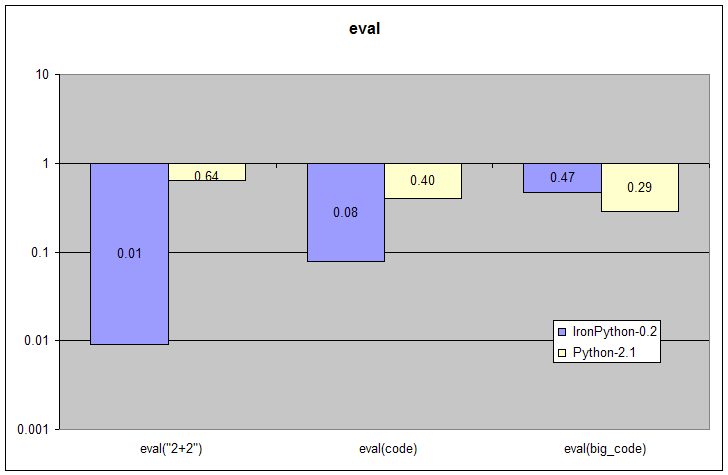
| Initialization | NONE | code = "[%s]" % ",".join(["100"]*100) | big_code = "[%s]" % ",".join(["100"]*2000 |
| Test | eval("2+2") | eval(code) | eval(big_code) |
These three tests dynamically compile, load and run programs provided as strings of different sizes. It is unsurprising that this would be slower on IronPython than on CPython (the standard Python-2.3 implementation built in C). Both systems must parse and compile the strings to their respective bytecodes. IronPython includes the additional step of loading that bytecode into the CLR where it is further translated into optimized machine code. The CLR's dynamic loading has been correctly optimized for loading whole new libraries or at least large classes and not for a single function to compute 2+2.
IronPython's speed isn't so slow in absolute terms. On the test machine it takes about 2 milliseconds to execute eval("2+2"). This is more than fast enough for interactive use. IronPython's performance is about 50x faster than it needs to be before it would be noticeable to an interactive user for a single call to eval.
I believe that it is worthwhile to sacrifice a little speed on eval in order to improve the overall performance of larger applications. However, performing 100x slower than an existing implementation on any operation is a potential show-stopper. This is a part of IronPython that can benefit from further optimization either to IronPython itself or to the underlying CLR.
The Whidbey release of .NET is expected to include support for "light-weight code generation" that could offer significant performance boosts to the performance of eval with minimal changes to IronPython's implementation. Another possible solution to this problem is to add a traditional interpreter mode to IronPython that bypasses IL generation to directly evaluate single expressions. This would be a LOT faster but it would require having two implementations of IronPython's semantics; one in the compiler to IL and a separate implementation in the dynamic interpreter. This would correspondingly increase the development, testing and maintenance work required for the IronPython project.
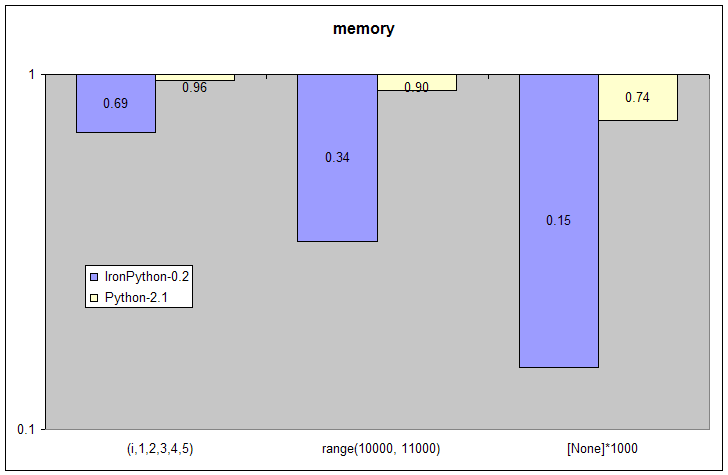
Here we test the speed of creating and destroying standard library objects over and over again. In all of these tests IronPython is slower than CPython, sometimes by a considerable amount. I believe that the primary reason for this performance hit is the difference between a general-purpose and a special-purpose garbage collector. CPython's integers, for example, have a highly tuned special purpose memory management scheme just for these objects because they are known to be created and destroyed very frequently in Python programs. Under the CLR, Python's integers are implemented as just another class like and the garbage collector makes no special optimizations for them.
My suspicion is that this is one area that IronPython will be slower than CPython for a while. I hope that I will be proven wrong by improvements to the speed of the CLR's garbage collector or by innovations in the implementation of Python's integers for that platform. Nevertheless, this memory management performance hit is usually more than made up for by the improved performance of other parts of IronPython as shown by the pystone benchmark and the rest of the micro benchmarks in this paper.
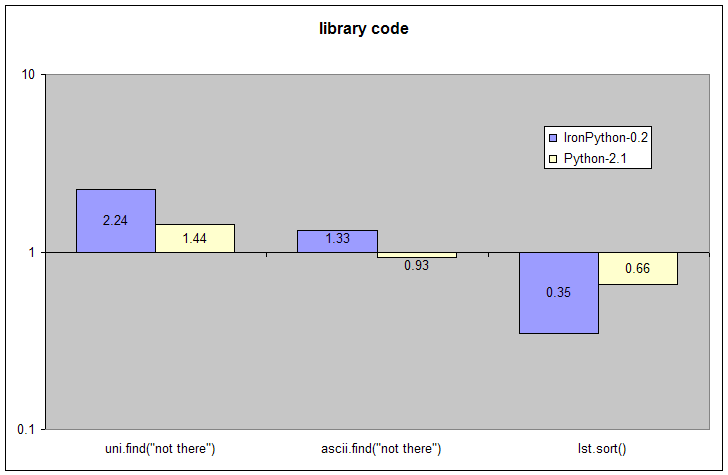
| Initialization | uni=unicode("not the xyz"*100) | ascii="not the xyz"*100 |
lst = [16,18,27,13,5,14,9,28,12,17,19,22,21,4,20,2,8,7,24,3,0,11,26,25,1,10,6,29,23,15] |
| Test | uni.find("not there") | ascii.find("not there") | lst.sort() |
These tests explore an extremely common case for Python programs. In each test virtually all of the time is spent not in Python code itself but in underlying library code written in C or C#.
The first two tests search for a small string inside of a large one. For CPython this code is implemented in C as part of the string object. For IronPython this is a call to the System.String.IndexOf(String) method in the standard CLR library. My conclusion here is that more time was spent carefully optimizing this code for the CLR library which led to a more efficient implementation. The greatest performance win is for find in unicode strings which is unsurprising as these are a fundamental part of the CLR but a relatively new addition to CPython.
The last test explores the speed of sorting a list of 30 ints. For CPython the time is spent in the C code that implements the sort method for list objects. This code has been highly tuned over many years. There's a substantial speed-up since 2.1 as Tim Peters has invested a lot of time designing and implementing a very fast sort function tuned to Python. There is even a special performance test in Lib/test/sortperf.py just for tuning sort performance. On the other hand, IronPython simply makes a call to the CLR library function System.Array.sort(object[], int, int).
In the short run, I expect that many of these kinds of tests will be "won" by CPython. The standard library for CPython has been under development since 1990 and that work has been driven by the specific needs and contributions of Python programmers. The CLR's standard library is much more recent, although it's hard to pin down an exact date for its first release.
In the long run, I'm convinced that these kinds of library benchmarks will all be won by IronPython. For example, consider the problem of IronPython's poor performance sorting lists found here. There are two ways this performance can be improved. One would be to take Tim's excellent algorithm and port it to C# specifically for IronPython. This would take some work, but far less than was required to develop it in the first case. This approach might be required for some extreme cases. However, the best approach is just to sit back and wait for the hundreds of man-years of work that Microsoft, Novell and others are investing in improving the CLR to bear fruit and speed up this and other operations with no specific IronPython work whatsoever.
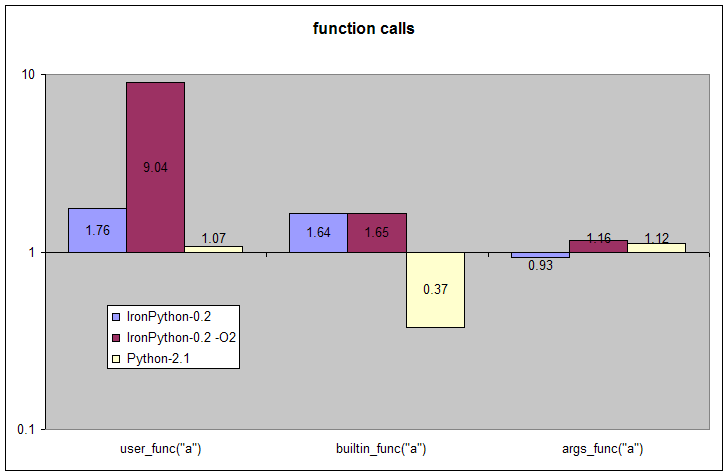
| Initialization | def user_func(x): return x | builtin_func = ord | def args_func(*args): return args |
| Test | user_func("a") | builtin_func("a") | args_func("a") |
This test looks at calling three different functions. This is the only test where the performance of IronPython is noticeably different with and without the -O2 option so this is the only test where those results are shown. The three different functions show very different relative performance.
The greatest performance improvement comes from using IronPython with the -O2 option and the CLR's native stack frames. This avoids creating Python specific stack frame objects for each function or method call. The price of this optimization is that it requires disabling the locals() builtin function and the frame.f_locals field. Beyond the performance improvement, this optimized implementation has some nice properties for integration with other languages and tools that support the CLR. For example, when Python local variables are stored in CLR local variable slots any CLR debugger will easily let you inspect and alter them.
My hope is that it will be possible to use native stack frames as the default implementation for IronPython in the future. It should be possible to use the CLR's debugging APIs to recover the information for locals() when needed. Given the support in the CLR for just-in-time debugging it may be possible to provide this without any performance overhead to the application except when locals() is actually used. I haven't had time yet to confirm if such an implementation is possible.
The second level of performance improvement is seen even without -O2 and is present for calling both user-defined and builtin functions. This smaller but still significant performance boost comes from fast-paths in the code to avoid creating a tuple object when calling a method with a small number of arguments. These fast-paths are produced by custom Python scripts that generate extremely repetitive but fast C# code for function calls with 0-7 arguments on functions defined with 0-7 parameters. Functions with 8 or more parameters use slower general-purpose code; however, these make up a small fraction of most Python systems and usually have larger bodies that will consume far more time than the function dispatch itself.
The last test shows calls to a function that explicitly requires its arguments to be collected up in a tuple. These functions are less common, but can be found in virtually all Python applications. IronPython implements calls to these functions using general-purpose code that has roughly the same performance as CPython's function dispatch code.
IronPython is faster than CPython or roughly equivalent for all of the function call tests. This is only true because none of these function calls is implemented using either System.Reflection.MethodInfo.Invoke or System.Type.InvokeMember to call these functions reflectively. Code-generation or delegates are used to implement all of these function calls instead. If reflective calls were used here the performance would be much worse.
This category of tests provides a good overview of IronPython's general optimization strategy. First, try to use native CLR constructs whenever possible. Second, use compile-time code generation to produce fast-paths for common cases. Third, fall back to fully dynamic implementations for the less common cases or where Python's semantics requires a fully dynamic implementation. Finally, test the performance of every CLR construct used and find alternatives when performance is unacceptable.
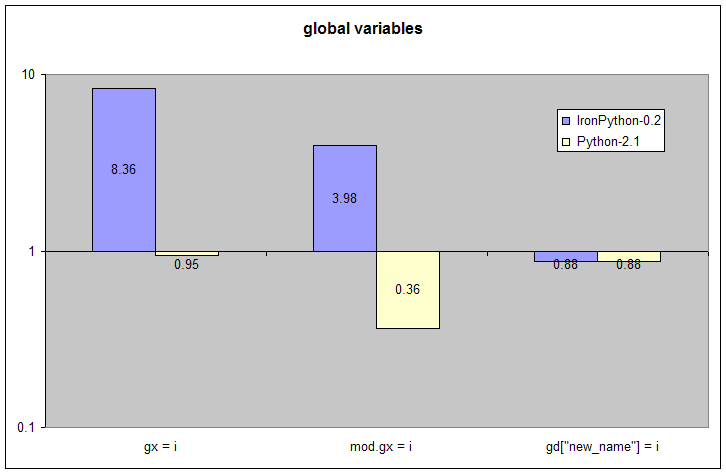
| Initialization | global gx | import __main__; mod = __main__ | gd = globals() |
| Test | gx = i | mod.gx = i | gd["new_name"] = i |
This category looks at the performance of three different ways to set the value of a global variable. In this category all three tests have exactly the same behavior but potentially different underlying implementations. In the CPython implementation, all three of these different ways to set a global variable have similar performance because they are all implemented using a dictionary for the global namespace. IronPython takes the same approach to optimization as for function calls to produce the fastest code for the common cases while continuing to support the most dynamic semantics of Python.
For the most common case of "gx=i", IronPython implements this as setting a static field defined on a module class. Static fields are well optimized by the CLR and using them can produce the kinds of extreme 8x performance improvements seen here. The trick to using static fields is to make sure that the other more dynamic methods of working with globals continue to behave correctly.
The case of "mod.gx = i" can't use static field access directly because of Python's dynamic typing. This must be implemented as a dynamic field lookup uses a string as a key just as in CPython. However, the module itself has special fast-path code generated for all known global variables to map string names into corresponding fields. This fast-path produces almost a 4x speed-up over CPython.
Finally, IronPython must support using the globals() dictionary to get and set local variables. When this is done for an unknown name the implementation falls back on using a standard hash table just like in CPython. This case is much less common than the previous two and it is worth paying a small performance price here in order to achieve the speed-ups of the previous tests.
High system performance is the end result of hundreds of small decisions rather than a single large one. Much of IronPython's performance comes from careful consideration of performance in each design choice. I've found that profilers are generally useless for improving the performance of serious applications and that the only good route involves trying a variety of different implementation strategies and comparing their performance in both micro and macro benchmarks. That said, there were a few rules that served me well.
IronPython can run fast on .NET and presumably on any decent implementation of the CLR. Python is an extremely dynamic language and this offers compelling evidence that other dynamic languages should be able to run well on this platform. However, implementing a dynamic language for the CLR is not a simple process. The CLR is primarily designed to support statically typed OO and procedural languages. Allowing a dynamic language to run well on this platform requires careful performance tuning and judicious use of the underlying CLR constructs.
Copyright © 2004 by Jim Hugunin