JD Doak, David Moore, and James Schaefer are all members of the Safeguards Systems Group in the Nonproliferation Division at Los Alamos National Laboratory (LANL). Dr. Burr is a member of the Statistical Sciences Group in the Decision Applications Division at LANL.
We discuss the use of Python and SimPy to model material flow in nuclear processing facilities; we use the example of a fuel fabrication facility to emphasize our points. A fuel fabrication facility receives plutonium and uranium oxides and produces fuel bundles for reactors. The goal is to produce an accurate representation of the processing and material flow so that effective safeguards measures (e.g., the measurements and material balance closures for material accounting) can be integrated into the design of the facility. Early attempts at modeling the facility with a commercial simulation tool were abandoned because more flexibility in the implementation was needed than the tool could provide. The design of the facility is continually changing and the model needs to respond quickly to these changes. Python and SimPy provide the necessary flexibility and facilitate the conceptual development of the model without creating unacceptable run times. SimPy has provided a clean and concise simulation framework that has almost no impact on the clarity of the model and adds little to the codebase.
The example fuel fabrication facility receives plutonium and uranium oxides from outside the facility. The first stage of the processing is known as powder preparation (see Figure 1) where various processing steps are applied to the material while it is in powder form. An example of one of these steps, blending, blends the plutonium and uranium oxides in order to reduce the enrichment (i.e., plutonium concentration). After power preparation, the material enters the pellet fabrication stage where pellets are created from the powder and treated in various ways (e.g., they pass through a sintering furnace). Pellets are stacked into fuel rods in the next stage, fuel-rod fabrication, and finally the fuel rods are made into assemblies and packaged for shipment during the assembly stage.
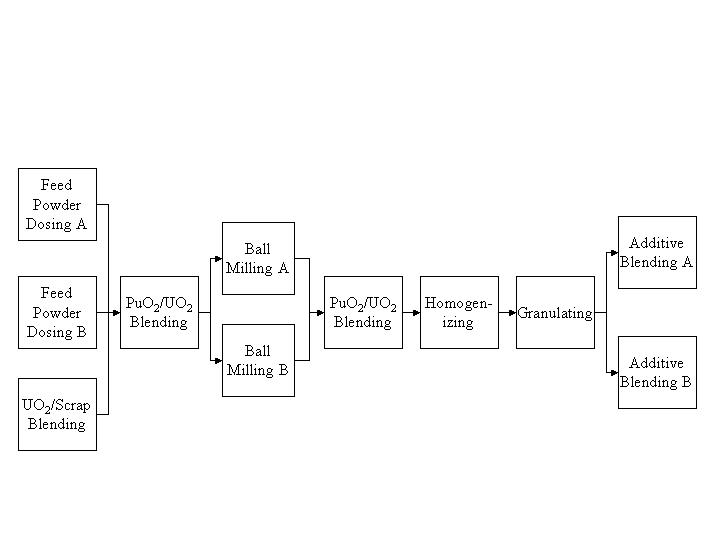
The magnitude of sigma-ID (Inventory Difference) is one of the biggest concerns from a safeguards point of view. Sigma-ID is essentially the amount of material the operator of the facility is unable to account for, given whatever safeguards program is in place. More specifically, ID is the measured difference between outputs and inputs with adjustments for inventory changes. Sigma-ID is the measurement error standard deviation of the ID. The results of the modeling and analysis are used to design the measurements (what type, when, and where), the sub-MBA (Material Balance Area) structure (i.e., which processing areas to group together), and frequency of balance closures (i.e., how often to calculate sigma-ID for the sub-MBAs) that then comprise the safeguards strategy of the facility. For example, we can determine that, if balance closures are not performed at least every x days for a particular sub-MBA, the sigma-ID will be unacceptably high.
The unit of operation in a nuclear facility is referred to as a glovebox and, in terms of the modeling, was the critical abstraction to "get right." It is a sealed area within a facility where processing occurs. Material (usually in a container) is processed in an "upstream" glovebox and then shipped either to a storage area or directly to a "downstream" glovebox. The glovebox serves to minimize contamination of the facility from processing by-products (e.g., grinding dust).
Our initial attempts at modeling nuclear processing facilities were with a commercial modeling tool. However, our experience has been that design changes are frequent. While attempting to reflect changes in the models, it became clear that the tool was simply not well suited to rapidly making extensive changes to highly-detailed models. Additionally, the models were not clear and transparent. I.e., it was difficult to look at the "blocks" and "connections" and extract the abstractions used to create the models.
This led us to consider the use of a programming language for implementation. A programming language would give us the ability to quickly make extensive changes to a model while, if done correctly, providing implicit documentation on our implementation of a facility in terms of objects and their inter-relationships. Given the author's background with and preference for Python, this was the first choice that was considered. Fortunately, there was also a simulation framework, SimPy, written in Python that appeared easy-to-use with little overhead. The question, of course, was would Python/SimPy be fast enough for a full-year simulation of an intricate material processing facility?
A major consideration when designing the model was whether to create a new type for each glovebox, inheriting from a base "Glovebox" class (e.g., "BlendingGlovebox"), or to create a generic glovebox. In the generic glovebox approach, a specific glovebox is instantiated from input files that define the operation of that glovebox without creating an additional glovebox type. This can be looked at as a data-driven model. New gloveboxes are added simply by creating the input specification files. We have implemented the data-driven approach.
What follows is a high-level description of how we have implemented the model. The first part presents the facility object and the four different types of glovebox objects; these are the primary abstractions in the model. We follow this with a more detailed description of the "standard" glovebox; this type of glovebox actually processes material whereas the other three are more for utility.
The facility object (Facility) within the model represents an entire nuclear material processing facility. Its job is to initialize the simulation, instantiate and then activate all the gloveboxes, and finally start the simulation. It also needs to trigger periodic cleaning of all the gloveboxes. In addition, this object determines how long the simulation runs (a parameter obtained from the user) and when inventory is written. When inventory is written, all the material residing in the glovebox at that time is recorded. The facility object acts as a go-between for gloveboxes. For example, say I'm glovebox A and I just finished cleaning out my holdup. (For a description of holdup, see the writeup on the standard glovebox.) This probably means I've generated scrap material and waste and want to ship them to the appropriate downstream glovebox. I have the name of the glovebox that I want to ship to, but not a reference to the instantiated glovebox object. Facility can provide a reference to the actual glovebox given the glovebox's name. There is a method in the facility object that returns a reference to a glovebox given the glovebox's name. I.e., it acts as a naming service for gloveboxes.
The real workhorse within the facility is the glovebox abstraction. Currently, there are four types of gloveboxes that are used for different purposes. The "standard" glovebox (described in more detail below) represents an actual glovebox within the facility that processes material. It is equipped with a cyclone (vacuum) system for removing scrap in the form of dust. These gloveboxes take in a certain amount of material, process it, ship it on, and accumulate associated by-products like scrap and holdup. The "generator" glovebox was created to address this question, "How do we get material into the facility?" A generator glovebox creates cans of material, despite the fact that it receives no cans, allowing it to simulate the receipt of material by the facility. One of the generators is a plutonium and uranium oxide generator that simulates receipt of powder. Yet another kind of glovebox is the "sampling" glovebox. This simulates a sample of material being taken from a container and sent to an analytical laboratory where plutonium content is measured. It generates no by-products and does no processing of material. (The sample itself is sent to scrap processing and recycled back into the main processing flow after it has been measured.) The final type of glovebox is the "dummy" glovebox. It is nothing more than a placeholder. For example, say we're implementing a glovebox, Glovebox A, that ships to Glovebox B. We want to test the simulation with Glovebox A, but Glovebox B has not been written yet. Without a dummy glovebox representing Glovebox B, the simulation will fail when Glovebox A tries to ship its product to Glovebox B.
The "standard glovebox" model is the most complex of the gloveboxes. This type of glovebox receives the material needed to process a batch from gloveboxes that preceed it in the processing chain. (Upstream gloveboxes automatically ship cans to downstream gloveboxes when they have finished the processing of a batch, as opposed to waiting for a request.) In a 24-hour period, a glovebox is scheduled to perform certain batch operations, each of a specified duration. When it is time for a glovebox to process a batch, it first checks to see if it has enough material from its various suppliers before deciding to proceed. If it does not have enough material, the glovebox skips over this batch and does no processing. When it is time to process a batch and there is enough material, the material to be processed is moved from the cans that have been sent into the glovebox into the actual processing area of the glovebox. Once the batch is complete, the resulting material is put in a can (or cans) and shipped to one of the downstream gloveboxes. Also at the end of a batch, we move material into one of the by-product repositories (see Figure 2) associated with a glovebox. This is critical since it is the by-products that are the largest contributors to sigma-ID. Some material is moved into the scrap repository, equipment holdup, and glovebox holdup. Scrap material is gathered by a cyclone system that pulls particles out of the air. Equipment holdup is material that has become stuck in the processing equipment. Glovebox holdup is the material that is outside of the processing equipment but within the glovebox. If a certain number of scrap material containers become full, they are immediately shipped. I.e., we don't wait for a scheduled cleaning. Equipment holdup first fills up its unremovable part; then the removable part is filled up to a saturation point. Once saturation is reached, no more material can be added to equipment holdup. To understand what we mean by "unremovable holdup," note that some material which builds up in the processing equipment cannot be removed, like "unusable fuel" in an airplane's fuel tank. The model assumes that all of the unremovable accumulation occurs before any accumulation of removable material begins. (Again, this is like "unusable fuel" that accumulates in the bottom of the tank when you start filling, which is followed by removable fuel that the fuel pumps can actually pull out of the tank.) Glovebox holdup, on the other hand, never saturates. However, it operates like equipment holdup in that the unremovable part is filled first followed by the removable holdup. A consequence of filling the unremovable holdup first is that, if you have a cleaning before the unremovable holdup is filled, no material can be removed during cleaning. Another point to make about the standard glovebox model is that whenever a can enters or leaves the glovebox, we record all pertinent information (e.g., time of receipt) to a file.
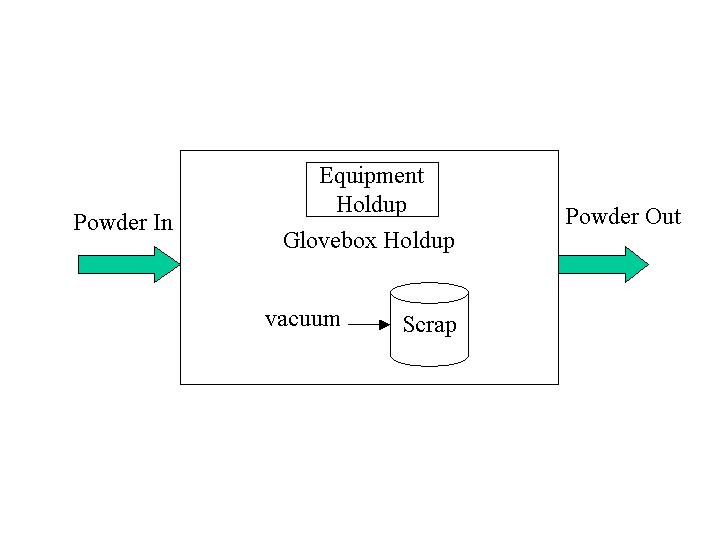
Gloveboxes need to be cleaned out; they are told by the Cleanup object (a SimPy Process) when to perform a cleaning. There are routine cleanings, such as filter changing, and an annual thorough cleaning. During a routine cleaning, all the scrap gathered by the cyclone system is removed and shipped to scrap processing. In addition, a portion of the equipment holdup is removed, split into scrap and waste, and shipped to the appropriate areas. In this model, no glovebox holdup is removed during a routine cleaning. In an annual cleaning, all of the scrap is removed as in a routine cleaning. Additionally, all removable equipment holdup and all removable glovebox holdup are removed. As in a routine cleaning, the glovebox and equipment holdup are split into scrap and waste streams and shipped on. Gloveboxes are also informed by the WriteInv object when they need to write out their inventory, which consists of material in cans waiting to be processed, material in process, scrap, equipment holdup, and glovebox holdup. There is no queue of cans waiting to be shipped since cans are shipped immediately at the end of a batch to the downstream gloveboxes. One final note about cleanings and inventory writings is that they are fully specified by the user in configuration files.
Note in the run method the use of SimPy constructs to initialize the simulation, activate the gloveboxes, and start the simulation.
"""
This class represents an entire nuclear material processing
facility. Its job is to initialize the simulation, activate all the
gloveboxes, and finally start the simulation. It also needs to
activate the processes that instruct gloveboxes when to perform a
cleaning or write their inventory. Plus, this class determines how
long the simulation runs (a parameter obtained from the user via a
script). The Facility object acts as a go-between for gloveboxes. For
example, say I'm glovebox A and I just finished cleaning out my
holdup. This probably means I've generated a can or two of scrap and
want to ship them to a downstream glovebox. I have the name of the
glovebox that I want to ship to, but not a reference to the
instantiated glovebox object. This is what the getGlovebox method
does.
Copyright 2004, Los Alamos National Laboratory, Univ. of California
Author: JD Doak, N-4
"""
from SimPy.Simulation import *
from ProjectX.Glovebox.Modules import Glovebox
class FacilityException(Exception):
pass
class Facility(object):
"""This class is a model of a facility where nuclear
material is processed.
"""
_gloveboxes = {}
def __init__(self, duration, cleanup, writeInv):
"""Initialize a new instance. For documentation
purposes, initialize _all_ member variables here.
Its a pain to have to look for all the variables
in the code.
Input values:
duration: how long will the simulation run,
in hours?
cleanup: the instantiated cleanup object.
writeInv: the instantiated writeInv object.
"""
self._duration = duration
# This needs to be an actual SimPy Process like
# a glovebox. The execute method of the Cleanup
# class will wait until it is time to do a cleanup,
# then tell all the gloveboxes to do a cleanup.
self._cleanup = cleanup
# Like Cleanup, WriteInv is a SimPy Process that
# tells the gloveboxes when to write inventory.
self._writeInv = writeInv
def run(self):
"""Initializes the simulation, activates all the gloveboxes,
then starts the simulation. (This is essentially all the SimPy
stuff.) We're also going to need a process that does
cleanups. This will need to be activated here also. And just
to make this more difficult, there will need to be a process
that schedules writes too.
"""
initialize()
for gbName in Facility._gloveboxes:
gbRef = Facility._gloveboxes[gbName]
activate(gbRef, gbRef.execute())
activate(self._cleanup, self._cleanup.execute())
activate(self._writeInv, self._writeInv.execute())
simulate(until=self._duration)
def getGlovebox(cls, gbName):
"""Return a reference to the instantiated glovebox object
named gbName.
"""
if not cls._gloveboxes.has_key(gbName):
raise FacilityException("""No glovebox in facility named "%s".""" \
% gbName)
return cls._gloveboxes[gbName]
getGlovebox = classmethod(getGlovebox)
def getGloveboxes(cls):
"""Returns a reference to the entire dictionary of
instantiated gloveboxes.
"""
return cls._gloveboxes
getGloveboxes = classmethod(getGloveboxes)
if (__name__ == "__main__"):
"""This is run by the mainline for developer unit testing."""
from ProjectX.Glovebox.Test import FacilityTest
FacilityTest.runTests()
Cleanup is an example of a SimPy Process. To be a SimPy Process, you must inherit from the Process class, call the Process.__init__ method within __init__, and have a method (essentially an execute method) that uses yield. In this case, we are using the "yield hold" command to delay between cleanings.
"""
This module contains a class that models a cleanup process within a
facility. It remains in a holding pattern until its time to do a
cleanup, either routine or annual. Then, it tells all the gloveboxes
to, well, cleanup.
Copyright 2004, Los Alamos National Laboratory, Univ. of California
Author: JD Doak, N-4
"""
from SimPy.Simulation import *
from ProjectX.Glovebox.Modules import Facility
CLEANUP_TIMES_FILENAME = "cleanup_times.dat"
class CleanupException(Exception):
pass
# "Process" indicates a SimPy process.
class Cleanup(Process):
"""This class implements a Cleanup abstraction
for use in simulations of nuclear facilities."""
def __init__(self, cleanupTimes):
"""Initialize a new instance. For documentation
purposes, initialize _all_ member variables here.
Its a pain to have to look for all the variables
in the code.
Input values:
cleanupTimes: each element of this tuple is
itself a tuple of (time, type)
where time is when the cleanup
should occur and type is either
routine or annual.
"""
# SimPy Processes must do this.
Process.__init__(self, name="Cleanup Process")
self._cleanupTimes = cleanupTimes
def execute(self):
"""Essentially, this gets called at the start of the
simulation and all cleanup events then get scheduled
and run.
"""
lastCleanup = 0
gloveboxes = Facility.Facility.getGloveboxes()
for time, type in self._cleanupTimes:
yield hold, self, (time - lastCleanup)
# Tell all the gloveboxes to do their cleanup.
for gbKey in gloveboxes:
gloveboxes[gbKey].doCleanup(type)
lastCleanup = time
if (__name__ == "__main__"):
"""This is run by the mainline for developer unit testing."""
from ProjectX.Glovebox.Test import CleanupTest
CleanupTest.runTests()
SimPy is a discrete-event simulation framework whose active objects are Processes. There are three Processes in our model: Glovebox, Cleanup, and WriteInv. Gloveboxes, when activated, operate on a 24-hour cycle. They wait between batches (and before the first batch and after the last batch); gather the material for processing at the beginning of a batch; wait until the end of the batch; and ship the output container and move material to the by-product repositories at the end of a batch. The Cleanup Process waits between cleanings (and before the first cleaning) and tells all the gloveboxes when it is time to perform a cleaning (routine or annual). WriteInv operates identically to Cleanup, but instructs gloveboxes to record their inventory instead of performing a cleaning.
Here is an example of an event that is recorded for a glovebox:
powder_in 1.000000 25.000000 3.000000 48 20.000000"powder_in" indicates that this line represents the receipt of a can into the glovebox. "1.000000" is the weight in kilograms of the plutonium in the can. "25.000000" is the total weight of the can, including the material and the can itself. "3.000000" is the simulation time, in hours, when the can was received. "48" is the unique identifier of the can. And "20.000000" is the weight of the empty can, also known as the tare weight. Other events that occur with a glovebox that are recorded are powder_out, a product container is shipped out of the glovebox; scrap_out, a scrap container is sent to scrap processing; waste, a waste container is shipped to waste processing; to_be_processed, a can that is in the glovebox whose material will be processed; in_process, material that is currently being processed; scrap_inv, scrap that is in the glovebox; glovebox_holdup, material that is outside of the processing equipment but within the glovebox; and equipment_holdup, material stuck in the equipment.
The biggest surprise is the speed with which the simulation runs. Using a three year-old linux box (1 gigahertz AMD processer, 256 Megabytes of RAM, and network mapped home dirs into which the data is written) and running the model for an entire year of operation, the simulation runs in less than a minute. Further performance analysis and optimizations have simply not been necessary because the run-time is well within acceptable limits.
The output of the simulation is a series of data files, one for each glovebox, as defined above in Results. These data files are read into a statistical software package, S-PLUS, where further calculations occur. Measurements, with both systematic and random errors, are added to the true material flow. Systematic errors are consistent errors (i.e., readings always too high or always too low) that are caused by, e.g., calibration errors. The variance that is caused by these errors is propagated through specific areas of the facility (i.e., a sub-MBA) to estimate the sigma-IDs for the sub-MBAs and the facility as a whole. Sigma-IDs that are too high may require adjustments to the type, frequency, and location of measurements; the size of sub-MBAs; and the frequency of balance closures. Having the data representing true material flow allows us to play "what if" games to design effective safeguard strategies for the facility.
The International Atomic Energy Agency (IAEA) uses a variation on the sigma-ID calculation called ID-D. We plan to compute ID-D to ensure that the safeguard strategies we recommend will be satisfactory to the IAEA.
Moving to a Python/SimPy implementation for this modeling work was an excellent choice. We are able to adjust rapidly to the changing design of the facilities; we can use the code itself as documentation for the class/object model; and the code runs well within acceptable time constraints. We have a framework that can, with some modifications, be used to model almost any nuclear material processing facility.
During this project, the team has made an effort to adopt Extreme Programming (XP) Methodologies. Much of the code for this project has been written in pairs. And a test-first (well, more like a test-simultaneously) strategy has been employed using PyUnit. In fact, after glancing through the 12 XP practices, we implement all of them, to a greater or lesser degree, except for the planning game. We would like to begin using the planning game and further refine the other practices in the context of our environment.
Before final delivery of the code, the current calculations that are done in S-PLUS need to be moved into Python. We are considering the use of the Python interface (R/S-PLUS - Python Interface) to the R statistical package (a freeware version of S-PLUS) to accomplish this. In addition, we are deciding whether the next effort will be on a GUI (basic) or further refinement of the model.
The primary author would like to acknowledge the support of Dr. Burr for his always-thorough statistical insights. He also acknowledges Mr. Schaefer and Mr. Moore for their willingness to pair program and collectively share code. Finally, the author thanks Mitch Chapman for his careful reading of the paper and helpful comments.