Advanced
Server Side Programming in Jython
S.Prasanna,
sprasanna199@gmail.com
1.
Introduction
This paper portrays a clear picture of Jython's capability in Server side
programming. It gives an introduction to Servlet programming and servlet filters
using Jython and discusses the advantages of using Jython for Server side
scripting.
2. Setting up the development environment
This section describes how to set up the development environment for using
Jython for server side programming.
I will start right from the basics i.e. Starting from Installing Jython and
then using it for Servlet Programming, for the sake of completeness.
Prerequisites:
Jython:
Version:2.1
Application
server: Tomcat 5 and above
All the programs described in this tutorial were tested on Tomcat 5.0.27 on a
Windows 2K box and the installation procedure described below will apply for
Tomcat 5.0 and above. Similar installation procedure can be followed for other
platforms with minor changes.
Installing Jython:
1. Download the class file jython_21.class.
2. Run
the class file using the command
java jython_21
3.
Specify the Jython installation directory during installation. I am assuming
the convention <JYTHON_HOME> for the Jython installation directory.
4. Once the installation is complete, change the environment variable settings
in Windows 2K and above.
In Windows 2K, right click My Computer -> Properties -> Advanced -> Environment Variables.
In the Environment variables, click New and add a new variable PATH and set its value to <
JYTHON_HOME> . If there is already
a PATH environment variable, then edit it
and append <JYTHON_HOME> at the end.
Now test the Jython
configuration by invoking the jython interpreter (using Start -> RUN -> jython).You should see the jython command line
interpreter in the command window. Similarly test the functionality of jythonc by opening a new command
window and type jythonc. You should see the jythonc compilation options.
Now you are ready with jython programming.
Installing Tomcat (Version 5.0 and above):
Installing
Tomcat is a fairly easy task and I recommend you to follow the one of the best Tomcat installation
guide available in the Web here. You should be able to
run Tomcat without any hiccups if you follow those procedures.
Make sure you have set the CLASSPATH.
In Windows 2K and above, right click My Computer -> Properties -> Advanced ->
Environment Variables.
Add or edit the CLASSPATH variable to have the jar files necessary for servlet compilation. Make
sure that the CLASSPATH environment variable contains the current directory by including ".".
Example:
CLASSPATH = .;<CATALINA_HOME>\common\lib\servlet-api.jar;
<CATALINA_HOME>\common\lib\jsp-api.jar;
Tomcat and Jython Servlets:
I am assuming that you have installed the Tomcat server based on those guidelines.
Now you have a working version of Tomcat (5 and above) and Jython 2.1. Follow the
below steps for using jython with Tomcat. Here after <CATALINA_HOME> will
denote the Tomcat installation directory.
There are many ways to integrate Tomcat with Jython [1], but I follow the
procedure below for developing Jython servlets.
The easiest way is to have Jython and Tomcat in their directories and
dictating Tomcat to use Jython class libraries to handle Jython servlets. This is
achieved as follows.
1. Edit the <CATALINA_HOME>/conf/web.xml and add these following lines.
<servlet>
<servlet-name>PyServlet</servlet-name>
<servlet-class>org.python.util.PyServlet</servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>PyServlet</servlet-name>
<url-pattern>*.py</url-pattern>
</servlet-mapping>
This defines the way the Jython servlets should be handled. The PyServlet
class is invoked to handle Jython servlets i.e files with a .py extension.
Note:
The above servlets and the mapping can also be defined in the context's
web.xml file. If your default context is ROOT (in Tomcat 5), then you may add
the above lines in that context's web.xml file.i.e <CATALINA_HOME>
/webapps/ROOT/lib/Web-inf/web.xml so that Jython servlets will be invoked
only for that particular context.
2. Copy the jython.jar file in the <JYTHON_HOME> directory to <CATALINA_HOME>/common/lib
directory. This is necessary for
PyServlet to handle Jython servlets.
3. Edit the <CATALINA_HOME>/bin/catalina.bat file (catalina.sh in Linux)
and add the following lines.
set CATALINA_OPTS=-Dpython.home=<JYTHON_HOME>.
This specifies the Jython installation directory from where Jython libraries
can be used.
Testing a Simple Jython Servlet:
Now its high time to test your configuration using a Test Servlet.
Copy the below file in the <CATALINA_HOME>/webapps/ROOT directory.
Listing 1: TestServlet.py
#TestServlet.py
from javax.servlet import http
class testservlet (http.HttpServlet):
def doGet(self, req, res):
#Handle Get Method
#Set Response ContentType
res.setContentType("text/html")
#Get a new Writer to print the Response in the browser
toclient = res.getWriter()
toclient.println("""
<html><head>
<title>Jython Servlet</title>
</head><body>
<div style="text-align:
center;"><span style="font-weight: bold;"><br>
Your Jython servlet configuration is Successful</span><br>
</div></body></html>
""")
Start the Tomcat server and type
http://<Server IP address:Port>/TestServlet.py
If you are using loopback address, then type
http://127.0.0.1:8080/TestServlet.py
You should see the message like this in your browser.
Your Jython servlet configuration is Successful
If you see the above message, then Congrats. Your Jython Servlet Configuration
was Successful. You are ready to program Jython Servlets.
3. Request Filters
Now we will see a servlet filter which blocks requests temporarily if the
number of requests exceed a threshold value within a specified time interval.
Listing 2:
RequestFilter.py
#RequestFilter.py
#This servlet filter will block requests from the client
#temporarily if it exceeds a specified limit within a
#specified time
from javax import servlet
from javax.servlet import http
import time , thread , sys
#To Keep track of Blocked IP addresses and to track all Requests
block_list = {}
Request_tracker = {}
done = 0
#Number of Requests which are allowed within a particular time (in seconds)
#If there are more requests within time TIME , that client IP is
#blocked for BLOCK_TIME seconds
MAX_REQUESTS = 20
TIME = 10
BLOCK_TIME = 60
CLEAN_UP_TIME = 20
def clean_tables():
global block_list , Request_tracker
#This function is called as a thread from the main routine
#Its function is to frequently clean up the block_list and Request_tracker
#from unwanted entries.This is done to avoid
#outdated entries in both the tables since these tables
#are altered only when the client makes a request
while 1:
time.sleep(CLEAN_UP_TIME)
print "Cleaner thread Invoked at " , time.ctime(time.time())
try:
#Clean up Entries in Request_tracker list if
#there is no client request for a time > TIME + 10
#i.e this entry is timed out
for entries in Request_tracker.keys():
if (time.time() - Request_tracker[entries][1] > TIME + 10 ):
del
Request_tracker[entries]
print "Deleted entry " , entries , " from Request_tracker "
except:
pass
try:
#Clean up Entries in block_list if
#there are no client requests for a time >BLOCK_TIME + 10
#i.e this entry is timed out
for entries in block_list.keys():
if (time.time() - block_list[entries] > BLOCK_TIME + 10 ):
del block_list[entries]
print "Deleted entry " , entries , " from block_list"
except:
pass
def Track_Request (client_request):
global block_list , Request_tracker , done
#Global variables are used so that they are in memory
#even after the filter processes a client's request
#and exits.This is useful for Subsequent processing
done = 0
#If the request_tracker has Client's IP as key
#then track the request
if Request_tracker.has_key(client_request):
#Increment the number of connection attempts
Request_tracker[client_request][0] = Request_tracker[client_request][0] + 1
if ( time.time() - Request_tracker[client_request][1] >= TIME ):
#If the difference between the current time and the
#time of last request exceeds the specified TIME limit
if (Request_tracker[client_request][0] > MAX_REQUESTS):
#If more than MAX_REQUESTS requests are made within that
#time,add that IP address to the block_list
block_list[client_request] = time.time()
#Time at which the address is added to the block_list
del Request_tracker[client_request]
#Delete that entry from Request_tracker as it is
#already added to block_list
return 1
else:
#If the client has not made requests > MAX_REQUESTS
#within time TIME , remove that client's IP address
#from the block list as it is a legitimate IP
del Request_tracker[client_request]
return 0
else:
if (Request_tracker[client_request][0] > MAX_REQUESTS):
#If the number of requests exceeds MAX_REQUESTS within time
#TIME,then add the client's IP to the block list
block_list[client_request] = time.time()
del Request_tracker[client_request]
return 1
else:
return 0
#New client accessing the server
#Keep track of the IP
list = [ 1 , time.time() ]
Request_tracker[client_request] = list
return 0
def check_block_list (client_request):
global block_list , Request_tracker
#Use global variables (associative arrays)
#block list and Request_tracker
if (block_list.has_key( client_request )):
#If the block_list contains client's IP as key
#If the difference between the current time
#and the time at which the IP address was blocked
#exceeds BLOCK_TIME , that IP address is released
#from the block_list
if ( time.time() - block_list[client_request] > BLOCK_TIME ):
del block_list[client_request]
return 0
else:
return 1
else:
return 0 #IP address not in block list
class RequestFilter (servlet.Filter):
def doFilter(self, req, res,chain):
global block_list , Request_tracker
done = 0
remote_addr = req.getRemoteAddr()
#IP address in block list, access temporarily suspended
if check_block_list (remote_addr) == 1:
res.sendError(403, "DOS Attempt, temporarily blocked")
#Here an error code 403 is used to
#indicate temproary blocking of IP
done = 1
#Finished processing client's request , exit
if done == 0 and Track_Request (remote_addr) == 1:
res.sendError(403, "DOS Attempt, IP temporarily blocked ")
done = 1
if done == 0:
#Legitimate request , access allowed
chain.doFilter(req,res)
def init(self, config):
#Initialize filter
print "Request Filter Initialized"
#Start a new thread to clean up entries
#at frequent intervals
thread.start_new_thread(clean_tables,())
def destroy(self):
print "Request Filter Destroyed"
sys.exit(0)
Copy the above file in the <CATALINA_HOME>/webapps/ROOT/web-inf/classes
directory and compile it using jythonc compiler as follows.
jythonc
-w. RequestFilter.py
Add the filter definition and mapping in <CATALINA_HOME>/webapps/ROOT/web-inf/web.xml file.
(See here)
<filter>
<filter-name>RequestFilter</filter-name>
<filter-class>RequestFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>RequestFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
You will see two class files generated in the <CATALINA_HOME>/webapps/ROOT/web-inf/classes directory as shown
below.
1.RequestFilter.class
2.RequestFilter$_PyInner.class
Start the Tomcat Server and note the filter initialization message to make sure that the
filter started.
Open the browser and access any page from the Tomcat server. Say
http://<Server
IP address:Port>/<FileName> or even the Tomcat Home page i.e http://127.0.0.1:8080
Keep reloading the page fast and when the number of requests exceeds a specific
threshold within a specified time interval,say 20 requests within 10 seconds,
etc , the request from that client will be blocked for two minutes.
There are two lists in the code namely the block_list and the Request_tracker
list. The request_tracker list monitors the requests and if any rule is violated
within a specified time interval , that requested IP is moved to block_list so
that the request will be blocked for the next two minutes.
Note that a thread was started during the Filter initialization like this.
thread.start_new_thread(clean_tables,())
This thread cleans the two lists namely the Request_tracker and the
block_list from unnecessary entries which will add to additional
processing overhead. This thread will clean the tables every 20 seconds.
The reason is that only when requests are made, entries in these tables are
processed. There may be a situation in which certain IP may make less requests
or single request or even if a request IP is block listed, it will be released
from the block list only after that IP makes a request after some time. This will
result in unwanted entries in the two lists.To avoid this situation, the thread
cleans up the tables once an entry is timed out .
Note:
Generally in thread programming, a parent process invokes a thread and whenever
the parent process dies before the thread it started, the thread it started
(child thread) also
ceases execution.I noticed this sort of behaviour in CPython. But in our case (In Jython),
the filter init method starts a thread .
thread.start_new_thread(clean_tables,())
This thread keeps on executing irrespective of the execution of the filter code. i.e
even if the Filter code processes a request and exits, the jython thread invoked
during the init method will keep on executing the function clean_tables
every 20 seconds, cleaning up the tables. Even if I shutdown the server, this thread will keep on
executing without the server being shutdown. That's why the method sys.exit(0) was used in the filter
destroy method which forces the server to quit.
def destroy(self):
print "Request Filter Destroyed"
sys.exit(0)
4. Working with POST method : A File Upload Servlet
Till now we have seen how to handle and process requests using the GET method
i.e by invoking the doGet method. Now we will see an example of how to invoke
the POST method i.e doPOST. Before that one needs to understand the difference
between GET and POST methods.
Both the GET and POST methods send data to the server, but when GET method is
used, the data is encoded with the URL and sent as parameters (name:value pair)
along with the URL which can be seen in the browser. The GET method has a
restriction with the length of data it can send. (Max 1024 bytes).
When POST method is used , the data sent to the server will be in the body of the
HTTP request. These cannot be seen in the browser and only the request
URL shows up in the browser. The content length of the POST method is unrestricted.
POST method is used in uploading files, storing or updating data in server, etc,
whereas GET method is used for tasks which are idempotent (i.e if you use
multiple GETs, you are likely to get same results).
Below is a File Upload servlet implemented in Jython which will handle all kinds
of files from the client and upload it to the directory where the File Upload servlet runs.
This servlet can upload both text as well as binary files.
Listing 3:
fileload.py
#fileload.py
#File Upload Servlet
#This Servlet Uploads a file from the client machine
#into the Directory in Server box where it runs
#This File Upload Servlet works for both binary as well as text files
from javax import servlet
from javax.servlet import http
from java.io import *
from java.util import *
from java.lang import *
from jarray import array , zeros
import string , pickle , os
#Server IP and Port address
SERVER_IP = "127.0.0.1"
SERVER_PORT = "8080"
#Global variables to have session details
session_id = 0
session = 0
done = 0
#done is a flag to indicate that the request from the client has been processed
def sub_array ( main_array , end_array ):
#This function returns the index within main_array where the end_array
#which is embedded within the main_array starts
#If no such array is embedded , it returns -1
i = len (main_array) - 1
k = len (end_array) - 1
while 1:
j = k
while ( j >= 0 ):
if ( end_array[j] == main_array[i] ):
i = i - 1
j = j - 1
if ( j < 0 ):
j = - 1
break
if ( i >= 0 ):
continue
else:
return (-1)
else:
break
if ( j == -1 ):
return ( i + 1 )
else:
i = i - 1
if ( i >= 0 ):
continue
else:
return (-1)
class fileload (http.HttpServlet):
def doGet(self, req, res):
global session , session_id , done
done = 0
#Get all Request parameters and Convert it to Java String format
parameters = str(req.getParameterNames())
parameters = String(parameters)
#Check if there are no parameters
parameters = parameters.indexOf("EmptyEnumerator")
#If there are no request parameters, the default Login screen is displayed
if parameters != -1:
res.setContentType("text/html")
toclient = res.getWriter()
toclient.println(
"<html><head>File Upload Servlet</head><body>"
+
"<FORM ACTION=http://" + SERVER_IP + ":" + SERVER_PORT +
req.getRequestURI() +
"""
" ="">
<p> </p><p> </p>
<center> UserID <input name="userid"
type="text"><br>
</center>
<div style="text-align: justify;">
<center> Password <input name="password"
type="password"><br>
</center><br></div><br>
<center> <input value="LOGIN"
type="submit"></center><p></p>
</form></body>
</html>
""")
done = 1
#Finished with Processing the client
#If User ID and Password were provided, the file Upload screen is displayed
UID = req.getParameter("userid")
password = req.getParameter("password")
if (done == 0 and UID != None and password != None):
if UID == "admin" and password == "admin":
session = req.getSession()
session_id = session.getId()
res.setContentType("text/html")
toclient = res.getWriter()
toclient.println(
"<FORM ACTION=http://"
+ SERVER_IP + ":" + SERVER_PORT + req.getRequestURI()
+ " ENCTYPE=multipart/form-data METHOD=POST>"
"""Enter the name of the File <INPUT TYPE=FILE NAME=file>
<BR>
<INPUT TYPE=SUBMIT value = "Upload">
</FORM>
""")
URL = "http://" + SERVER_IP + ":" + SERVER_PORT + req.getRequestURI() +
"?logout=1"
toclient.println("<A HRef=\"" + URL + "\">")
toclient.println ("Logout</A>")
toclient.println("</body></html>")
else:
#Authentication failed
res.setContentType("text/html")
toclient = res.getWriter()
toclient.println("<html><body>")
toclient.println("<BR> Authentication failed ")
URL = "http://" + SERVER_IP + ":" + SERVER_PORT + req.getRequestURI()
toclient.println("<A HRef=\"" + URL + "\">")
toclient.println ("<BR>Goto LOGIN page</A>")
toclient.println("</body></>")
done = 1
#Finished with Processing the client
logout = req.getParameter("logout")
if ( done == 0 and logout != None ):
#User logs out, Current Session Invalidated
try:
session.invalidate()
session_id = 0
res.setContentType("text/html")
toclient = res.getWriter()
toclient.println("<html><body>")
toclient.println("<BR> You are Logged out")
URL = "http://" + SERVER_IP + ":" + SERVER_PORT + req.getRequestURI()
toclient.println("<A HRef=\"" + URL + "\">")
toclient.println ("<BR>Goto LOGIN page</A>")
toclient.println("</body></html>")
except:
#Logout attempted after a session was already invalidated (Invalid
session)
res.setContentType("text/html")
toclient = res.getWriter()
toclient.println("<html><body>")
toclient.println("<BR> Invalid session")
URL = "http://" + SERVER_IP + ":" + SERVER_PORT + req.getRequestURI()
toclient.println("<A HRef=\"" + URL + "\">")
toclient.println ("<BR> Goto LOGIN page</A>")
toclient.println("</body></html>")
def doPost (self, req, res):
global done
#Flag to indicate that the request has been processed
done = 0
#Set Response type
res.setContentType("text/html")
contentType = req.getContentType() #Content-type (multipart/form-data)
toclient =
res.getWriter() #To write response to the client
(Browser)
if session_id == 0:
#Trying to upload file in an invalid session
toclient.println("<html><body>")
toclient.println("<BR> Invalid session")
URL
= "http://" + SERVER_IP + ":" + SERVER_PORT + req.getRequestURI()
toclient.println("<A HRef=\"" + URL + "\">")
toclient.println ("<BR> Goto LOGIN page</A>")
toclient.println("</body></html>")
done = 1
#Finished with Processing the client
if done == 0 and req.getContentLength() > 2000000:
#If
Content length exceeds 2000000 bytes, File Size exceeded message
#is displayed
toclient.println( "<html><body>")
toclient.println(" File size exceeded ")
toclient.println(" </body></html> " )
done = 1
if done ==
0:
#Get a new Stream for processing POST data contents
input = DataInputStream ( req.getInputStream() )
length = req.getContentLength()
#Get the exact path of the File (with respect to client system) uploaded
list = []
for i in range (4):
#These lines of the POST data contents contains header
#string, name of the file , etc
list.append ( input.readLine() )
boundary = String(list[0]).getBytes()
join_list = string.join(list[1], "" )
#boundary variable gets the unique Header String (Which also appears at
the end)
#This String is used to extract the Data portion of the file from the
#Stream
#Getting the Path information of the File uploaded
filepath = join_list[string.rfind(join_list,"=")+2:len(join_list)-1]
if filepath == "":
#No file was selected , Prompt for a File to be uploaded
toclient.println( "<html><body>")
toclient.println(" Please Select a file to upload ")
toclient.println(" </body></html> " )
else:
#Get the exact name of the file which was uploaded (from the path)
filename = filepath[string.rfind(filepath,os.sep)+1:]
exactfilename = filename
#os.sep is used in the above call so that the path separation characters
#for different platforms can be used to separate the file name from its
path
#for example \ or / for Windows / for UNIX, etc
#Create new Java byte array and initialize it to zero
buffer = zeros ( length , 'b' )
bytesread = 0 # Keep track of bytes read
#Read the entire bytes in the buffer
try:
while (1):
#Copy the contents in a buffer
buffer[bytesread] = input.readByte()
bytesread = bytesread + 1
except:
pass
input.close() # Close the Input Stream
#Write_boundary determines the index at which
#the data portion of the file uploaded ends
write_boundary = sub_array ( buffer , boundary )
#The sub_array function defined above returns an index within a
#main array till the start of another array (here boundary) is reached
#This is done to get the contents of data portion of the file
#from the whole array which is read from the DataInputStream
#i.e to separate file contents from the end header
filename = os.path.dirname(req.getRealPath(req.getServletPath()))
+"//"+ filename
#The above call is used to create the uploaded file in the same
directory
#where the servlet runs
#Create a New OutputStream
output = DataOutputStream ( FileOutputStream (filename))
#Now write the data portion of the file in the OutputStream
for i in range (write_boundary-2):
output.write (buffer[i])
output.close()
#Deallocate the buffer
buffer = None
toclient.println( "<html><body>")
toclient.println("File " + exactfilename + " Uploaded" )
toclient.println(" </body></html> " )
#Prompt the user in case of more file Uploads
if session_id != 0:
toclient.println(
"<FORM ACTION=http://" + SERVER_IP + ":" + SERVER_PORT
+
req.getRequestURI()+ " ENCTYPE=multipart/form-data METHOD=POST>"
"""Enter the name of the File <INPUT TYPE=FILE NAME=file>
<BR>
<INPUT TYPE=SUBMIT value = "Upload">
</FORM>
""")
URL
= "http://" + SERVER_IP + ":" + SERVER_PORT + req.getRequestURI()+
"?logout=1"
toclient.println("<A HRef=\"" + URL + "\">")
toclient.println ("Logout</A>")
toclient.println("</body></html>")
To test the servlet copy it in the <CATALINA_HOME>/webapps/ROOT
directory. You can also create a new directory in your ROOT folder and test the servlet,
in which case it will upload the file to the directory in which you ran the
servlet. Once you copied the file, test it using the following address in
the browser.
http://<Server IP address:Port>/fileload.py
or
http://127.0.0.1:8080/fileload.py
You will be prompted a user name and password and enter the value admin for
both. Then you can select the file and upload it. You can see the uploaded file in
the directory where the servlet resides. i.e in the <CATALINA_HOME>/webapps/ROOT
directory by default or any other directory from where the servlet is invoked.
I think you can easily follow the code with the comments. If you want to understand
how file upload takes place, i.e how the servlet processes the
POST data contents, headers, etc, then I recommend you to follow the below code which
will print all the headers and the contents of the file which was uploaded so that it
will aid you in understanding the working of the above servlet well.
Listing 4:
getpost.py
#getpost.py
#This Servlet prints the Contents
#of the POST data when a file is Uploaded from
#the client using a HTML FORM
#This helps in understanding how file uploads
#take place
from javax import servlet
from javax.servlet import http
from java.io import *
from java.util import *
from java.lang import *
import string
#Define Server IP address and Port number
SERVER_IP = "127.0.0.1"
SERVER_PORT = "8080"
class getpost (http.HttpServlet):
def doGet(self, req, res):
#Send a File Upload Page to the client
res.setContentType("text/html")
toclient = res.getWriter()
toclient.println(
"<FORM ACTION=http://" + SERVER_IP + ":" + SERVER_PORT + req.getRequestURI()
+ " ENCTYPE=multipart/form-data METHOD=POST>"
"""Enter the name of the File <INPUT TYPE=FILE NAME=file> <BR>
<INPUT TYPE=SUBMIT value = "Upload">
</FORM>
""")
def doPost (self, req, res):
res.setContentType("text/html")
toclient = res.getWriter()
toclient.println("Printing Request Headers:<BR><BR>")
names = req.getHeaderNames()
#Get all header names
while names.hasMoreElements():
#Get the value of each Header and send it
#to the browser
name =names.nextElement()
values = req.getHeaders(name)
if values!= None:
while (values.hasMoreElements()):
value = values.nextElement()
toclient.println(name + ": " + value + "<BR>")
toclient.println("<BR>Printing Stream contents:<BR><BR>")
#Now printing the Stream contents
input = BufferedReader(InputStreamReader(req.getInputStream()))
read_data = input.readLine()
#Print Start of the Stream header
toclient.println("Start of Stream = ")
toclient.println(read_data + "<BR><BR>")
#Now print POST data
while ( read_data != None ):
toclient.println (read_data)
last_read_line = read_data
read_data = input.readLine()
#Print end of Stream
toclient.println ( "<BR><BR>End of Stream = " + last_read_line)
#This is equal to the Start
of stream header
Access the above servlet (using http://<SERVER IP address:Port>/getpost.py or http://127.0.0.1:8080/getpost.py)
and select a file and submit it to the server. You
can see the headers and the POST data contents in the browser.
The only notable difference is if the
servlet is invoked using Internet Explorer 5, the the name of the file along with its path w.r.t
the client file system can be seen in the POST data contents whereas in browsers like Firefox,
only the name of the file selected is seen (but not its full path).
Having seen the above two servlets I am sure that one will be confident in handling
file uploads using Jython servlets. To get the file to be uploaded in the
directory where the servlet resides the below method was used,
req.getRealPath(req.getServletPath())
which would get the URI you used to invoke the servlet and its real path. Also to
make the above servlet platform independent the os.sep constant is used
which would construct the target path of the file
name independent of the platform in which the servlet runs.
One should also be a bit familiar with accessing Java arrays using Jython to understand it
easily. Sessions and logins are included in the above servlet make it understandable it in
a more professional way, i.e how to login to the server and how sessions are handled so
that the client can login, do some task and then log out.
5. Response Filters
So far we have seen Servlet filters processing requests. Now we will see how the
filter processes the response. Its natural to assume that since the requests
go via the filters, the response should also pass through the filters so that
the filters can modify and add response headers and data
without any problem. But it is not the case with response filters. The filter
should capture the response stream during the time it processes the request
(via doGet or doPost) so that it can process the response data. The following things
will make it clear.
Whenever the request reaches the end point (i.e HTML or servlet , etc) , the
response is written directly to the response stream or the output stream and it is
immediately flushed and the stream thus becomes invalid. Therefore when
the filters open the response stream for monitoring or modifying the response ,
an exception will be thrown like this.
java.lang.IllegalStateException:
getOutputStream() has already been called for this response
which means, the response stream was already opened and the response was sent
to the client via that output stream before the filter processed it.
For example the below Filter tries to capture the response stream in the above
mentioned fashion.
Listing 5:
CaptureResponse.py
#CaptureResponse.py
#A Response Filter to Capture and Modify the Response without Overriding
#This will lead to illegal state exception
from javax import servlet
from javax.servlet import http
from java.lang import *
from java.io import *
import string , sys
class CaptureResponse(servlet.Filter):
def doFilter(self, req, res,chain):
#Capture the Stream which writes response to the client
chain.doFilter(req, res)
toclient = res.getWriter()
def init(self, config):
print "Capture Response filter Initialized"
def destroy(self):
print "Capture Response filter Destroyed"
sys.exit(0)
The filter calls the getOutputStream method after it called the doFilter
method. If this filter is deployed and a static HTML page were accessed in the
server, an exception will be thrown as follows.
java.lang.IllegalStateException:
getOutputStream() has already been called for this response
which means that the OutputStream was already called and hence the Illegal
state exception.
Note:
When the target end point is a servlet, you won't get any exception , because in
that case , the response will not be flushed so that the filter can call the
getWriter() more than once, but it can only append data at the end of the
response and can't capture the target servlet's response data. In this
case the filter can modify the response headers and append its own data at
the end.
The solution to capture the response is to extend the HttpServletResponseWrapper class and pass it
to the target servlet or HTML and get the wrapped response from the target servlet or
HTML, overriding the getWriter method to get the response data generated by
the target servlet or HTML. This is illustrated in the figure below.
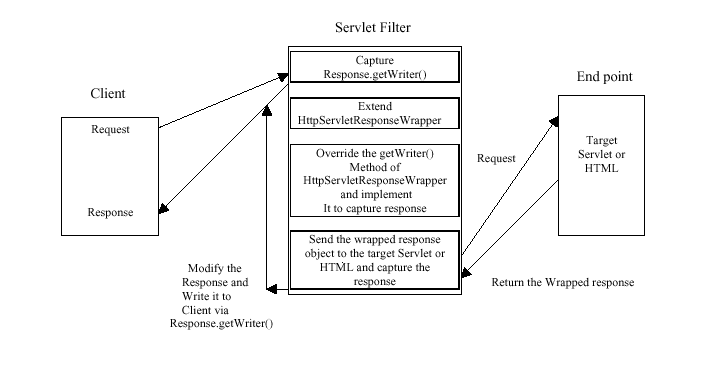
Figure 1: Response Filters
Here the filter first captures the stream so that it can write the response to
the client. Then it creates a new Object extending the HttpServletResponseWrapper
class and overrides the getWriter() method and defines it in such a way that it
can capture the response string from the target servlet or HTML. This object is
then passed to the target servlet or HTML and the getWriter() method defined by
this class is used instead of the super class's default getWriter(). This would
return the response string to the filter again so that it can modify the original
response. The listing for the response filter is shown below.
Listing 6:
ResponseFilter.py
#ResponseFilter.py
#A Response Filter to Capture and Modify the Response
from javax import servlet
from javax.servlet import http
from java.lang import *
from java.io import *
import string , sys
#Buffer contains the stand-in stream response generated by the target servlet or HTML
buffer = None
#Class Wrapper Extends Standard HttpServletResponseWrapper
class Wrapper(http.HttpServletResponseWrapper):
#Override the default toString method to capture the
#target servlet or HTML Response
def toString(self):
global buffer
return buffer.toString()
#Override the Standard getWriter method
#to have the response contents in a stand-in stream defined below
def getWriter (self):
global buffer
buffer = StringWriter()
return PrintWriter(buffer)
class ResponseFilter (servlet.Filter):
def doFilter(self, req, res,chain):
#Capture the Stream which writes response to the client
toclient = res.getWriter()
#Create the Wrapper object with its default constructor
wrapper_stream = Wrapper(res)
#Pass this Wrapper object to get the response from the target
#Servlet or HTML by overriding the getWriter method
chain.doFilter(req,wrapper_stream)
#Get the Wrapped Response
if (str(wrapper_stream.getContentType()) == "text/html"):
#If
response is HTML, set ContentType of Client Response to HTML
res.setContentType("text/html")
#Get the Response data in a string
wrapped_response = str(wrapper_stream.toString())
#Find the occurrence of end HTML tag in the response
if wrapped_response.find("</HTML>") <> -1:
#Append a message to this response
wrapped_response =
wrapped_response[:wrapped_response.rfind("</HTML>")] + """
<div style="text-align: center;"><font style="font-weight:
bold;"
size="+2"><BR> This Response was Monitored by the Filter
<BR></font>
<span style="font-weight: bold;">
""" + wrapped_response[wrapped_response.rfind("</HTML>"):]
#Send the Modified response to the client
toclient.println(wrapped_response)
else:
#If the end tag is </html>
wrapped_response =
wrapped_response[:wrapped_response.rfind("</html>")] + """
<div style="text-align: center;"><font style="font-weight:
bold;"
size="+2"><BR> This Response was Monitored by the Filter
<BR></font>
<span style="font-weight: bold;">
""" + wrapped_response[wrapped_response.rfind("</html>"):]
#write the modified
response
toclient.println(wrapped_response)
#Deallocate the buffer
buffer = None
def init(self, config):
print "Response Filter Initialized"
def destroy(self):
print "Response Filter Destroyed"
sys.exit(0)
Here the filter adds its own message (thereby modifying the response) and then
sends it back to the client via the getWriter() method it already called. Compile
the servlet and add the filter definition in the web.xml file as discussed above
for the previous filters. You can see the Response filter's data along with the
actual response you get. (A message "
This Response was Monitored by the Filter" appended at the end of every response)
Note:
Here the wrapped response object (which is extending the HttpServletResponseWrapper class) is invoked as
Wrapper(res)
This would call the default constructor of the super class HttpServletResponseWrapper
(which is the response object, res) . In Java, this would require another call.
super(res)
in the extended object to call the super class's (i.e HttpServletResponseWrapper)
constructor. This is not required in jython as it would implicitly call
the super class's constructor.
One can try this example by cascading many response filters. In that case,
every filter can modify the response and the final response sent to the
client will be the modified response of all the filters, by a similar analogy as
described below. Also in that case the first servlet filter will capture the
client's response stream.
6.
Servlet Context methods: Getting System information
Here we will see how to use the servlet context methods to get some information about the files and
directories.
The servlet context interface can be used to get all the directories and files in the
current servlet context (say ROOT) and their real path with respect to the
local system. The servlet below displays all the directories and files in the
current servlet context.The below servlet recursively gets all
the files and directories in the current servlet context.
Listing 7:
getFileDir.py
#getFileDir.py
from java.lang import *
from javax.servlet import *
from javax.servlet import http
import string , jarray
toclient = None
def recurse_directory (context,list_dir):
global toclient
for i in range(len(list_dir)):
if list(context.getResourcePaths(list_dir[i]).toArray()) == []:
#If the return value is empty list , it is a file
toclient.println("<BR>" + list_dir[i])
#Print the real path of the file
toclient.println("<BR>" + "Path = " +
context.getRealPath(list_dir[i]) + "<BR>" )
else:
#Directory found, recurse through the current directory
recurse_directory(context,list(context.getResourcePaths(list_dir[i]).toArray()))
class getFileDir (http.HttpServlet):
def doGet(self, req, res):
global toclient
#Set Response ContentType
res.setContentType("text/html")
#Get a new Writer to print the Response in the browser
toclient = res.getWriter()
toclient.println("The files
and directories in the current context are ....<BR>")
#Get the current servlet context
context = http.HttpServlet.getServletContext(self)
#Get the directory and the file listing for the above context
#at the topmost level
resource_path = list(context.getResourcePaths("/").toArray())
#Recurse through the current context to traverse all directories
recurse_directory(context , resource_path)
toclient = None
Copy the script in the ROOT directory <TOMCAT_HOME>/webapps/ROOT and access the servlet using
http://<SERVER_IP>:<PORT>/getFileDir.py
or
http://127.0.0.1:8080/getFileDir.py
and you will see all files in the current context with their real path. As obvious, not all files
displayed in the result are accessible via browser.
7. Advantages of Jython
1.Testing and debugging of servlets can be done with ease because of the interpreted nature of jython,
which prevents servlet recompilation and servlet reloading, thus drastically reducing
development time. Servlet reloading also destroys previously loaded filters during
server startup, thus the server has to be restarted once a servlet is recompiled in
java. Servlet filters can also be easily developed in jython since a jython code can
easily be compiled to java byte code. Infact this is the best application which uses Jython’s
interpreted nature and compilation capabilities.
2. Implicit type conversion of objects in Jython reduces the lines of code. Here
a simple Jython filter is used for illustration of the above statement.
1 from javax import servlet
2 from javax.servlet import http
3
4 class JythonFilter (servlet. Filter):
5
6 def doFilter (self, req, res,
chain):
7
8
remote_addr = req.getRemoteAddr () # This is a method of
ServletRequest
object
9
request_uri = req.getRequestURI () # This
is a
method of HttpServletRequest object
10
11 print
remote_addr, “ requested “, request_uri
12
13 def init (self, config):
14
15 print "Filter Initialised"
16
#Initialization code
17
18 def destroy (self):
19
20
print "Filter Destroyed"
21
#Clean up actions
From the above example the following point should be noted. The servlet filter
receives request and response of the type ServletRequest and in case of http –
specific capabilities, the method should be explicitly typecasted in Java to
HttpServletRequest.
This would mean that line 9 in java should be like
HttpServletRequest request = (HttpServletRequest) req;
String request_uri = request.getRequestURI ();
However in jython it gets converted implicitly when it is assigned to a variable.
3. Some Jython modules can also be tweaked to work with latest python modules.
For example, the way an XML parsing code in python (using pyXML) was successfully executed in jython is shown with
an example
here.
8. References and Further readings
[1] Jython for Java Programmers, By Robert W. Bill, New Riders Publications
[2]. Python Programming with the Java™ Class Libraries: A Tutorial for
Building Web and Enterprise Applications with Jython, By Richard Hightower,
Addison Wesley Publications.
[3] Jython Essentials, Samuele Pedroni and Noel Rappin, O'Reilly
Publications.
[4]
http://java.sun.com/products/servlet/Filters.pdf
(Servlet Filters Documentation).