PyBlosxom: A microkernel approach to blogging
Ted Leung
Introduction
This presentation gives an overview of the important aspects of PyBlosxom from a developer's point of view. My goal is to make it easier for people to write plugins for PyBlosxom and perhaps to attract some additional folks who are interested in working on the core system itself.
PyBlosxom is a weblogging/blogging system written in Python. It is based on a minimal core engine that has a few key characteristics:
- Blog posts are stored as individual files in a category-oriented hierarchy of directories on the filesystem of the blog's web-server. This means that no database software is required. Also, you can use the text editor of your choice to create and update your weblog postings.
- Lots of the functionality of PyBlosxom weblogs are provided via a plugin architecture. The core functionality of the PyBlosxom engine is around 3400 lines of Python code.
PyBlosxom got its name and inspiration from Rael Dornfest's Blosxom, which is written in Perl. In fact, there are a number of other Blosxom like packages written in various languages. All of the members of this family of blogging packages share the filesystem model and a plugin architecture of some sort.
PyBlosxom allows for several different permalink URI representations. The standard representation provides permalinks that include the year, month, and day of the weblog entry posting date. For example:
http://www.sauria.com/blog/2005/03/09/a-post
You can also use the hierarchical categories to provide the path to a posting:
http://www.sauria.com/blog/computers/internet/weblogs/pyblosxom/a-post
On my blog, both of these URIs refer to the same weblog posting. You can also look at groups of entries by removing information at the end of the URI:
http://www.sauria.com/blog/ shows the root of my blog http://www.sauria.com/blog/2005/03/09/ shows all posts dated on the 9th of March in 2005 http://www.sauria.com/blog/2005/03/ shows all posts in March in 2005 http://www.sauria.com/blog/2005/ shows all posts in 2005 http://www.sauria.com/blog/computers/internet/weblogs/pyblosxom/ shows all posts in the computers/internet/weblogs/pyblosxom category http://www.sauria.com/blog/computers/internet/ shows all posts in the computers/internet category
Another characteristic of Blosxom derived systems is the use of flavors. By appending a ?flav=<label> to the end of any PyBlosxom URI, you can specify what output format (aka flavor) you would like. The weblog world is full of potential output formats: HTML, XHTML, RSS (several different varieties), Atom, etc. The flavor system allows a PyBlosxom user to define a new flavor in order to produce output in one or more of these formats. Additionally, flavors can be theme-oriented: sunshine, rainy-day, purple-pie-man, etc.
A flavor consists of a series of templates which are assembled to form the completed output. Using this template system allows PyBlosxom users to use flavor templates built by users of other *osxom systems with only a few modifications.
The plugin system allows users to add functionality beyond what comes with PyBlosxom by default. PyBlosxom plugins have access to the information that the core engine has. They can read and introduce variables that appear in PyBlosxom templates, they can inject new entries into the rendering pipeline, they can render output, and they can even work with the HTTP headers that accompanied the request for a weblog page.
Here some examples of functionality that is provided via plugins:
- archives - create an access to archives, one link per month
- calendar nav - use a calendar as a way to navigate through archives
- xmlrpc - metaweblog - implement the Metaweblog XML-RPC API to allow fancy posting/editing UI
- http 304 handling - implement conditional HTTP handling to save bandwidth
- autoping - ping all referenced urls that have trackback or pingback URI's
- logging - log HTTP information to a file
- lucene - use Lucene to provide full text search
- handle text formatting of blog posts formatted using text+html, textile, or ReST
Configuration
There are two major areas the need to be configured when installing PyBlosxom: the web server connection and the PyBlosxom configuration file, config.py
Web server configuration
PyBlosxom can interface with a web server in a number of ways. Originally PyBlosxom was designed as a CGI script, but starting with PyBlosxom 1.2 PyBlosxom will also be usable from mod_python, Twisted, or any WSGI compliant server.
Occasionally, people need to use something like Apache's mod_rewrite in order to get the weblog to show up in the desired portion of the URI space.
The only other web server side issue is making sure that all of the PyBlosxom modules are available to the CGI or servlet.
The PyBlosxom Configuration File: config.py
PyBlosxom's configuration file is called config.py, and basically contains a dict named py, whose entries are the configuration variables for PyBlosxom. This dict ends up getting passed all the way through the core processing engine. Some of the important values that you need to set are
py['datadir'] the directory of the root of the PyBlosxom data, which will contain all the blog entries.
py['plugin_dirs'] a list of directories containing the plugins that you wish to use.
py['load_plugins'] a list containing the names of the plugins that you wish to use.
In order to use plugins you need to correctly set py['plugin_dirs'] and place the corresponding entry in py['load_plugins']
Once you have finished editing config.py to your liking, you can use pyblosxom.cgi to verify your installation from the command line:
pyblosxom.cgi
You will need to be careful about operating system permissions between the web server user and the user PyBlosxom is running as. This will affect comment files and logs especially.
PyBlosxom Architecture
PyBlosxom is implemented as a pipeline of plugins. The input to the pipeline is an HTTP request and the output is an HTTP response (most commonly containing HTML or RSS/Atom). There are abstractions to represent the HTTP request and response, the configuration information, the entries and other data stored in PyBlosxom.
In PyBlosxom, a plugin is a Python module. You define functions in the module, and PyBlosxom will call functions with a specific name at a well-defined point in the execution of the PyBlosxom pipeline. For example, a callback function named cb_start is called before most PyBlosxom processing begins. If your plugin module provides a function called cb_start, then it will be called.
PyBlosxom allows you to install many plugins, so a natural question is how do all those plugins interact. The py['load_plugins'] list serve two purposes. It tells PyBlosxom which plugins in the various plugin directories will actually get used. It also defines a sequential order in which plugins will be called. If you don't provide a value for py['load_plugins'] (you must still provide a value for py['plugin_dirs'] if you want to use any plugins), then PyBlosxom will load all the modules in all the plugin directories specified in py['plugin_dirs']. The plugins will be sorted by alphanumeric sorting on their names, and that will be the order in which they are called.
At a given callback point, every module function which provides a correctly named function will be called. So if you load five plugin modules and each module provides a cb_start function, then all five functions will be called when PyBlosxom reaches the start callback point. The order in which those five functions are called will be determined by the rules described in the previous paragraph. This allows multiple plugins to get access to data at the proper point during PyBlosxom's execution. It also allows plugins to exchange information if they know their relative ordering (it's best to use py['load_plugins'] in this case.)
For advanced usage, it is possible to change the way that chains of callback functions are processed. So instead of calling every callback function in the chain, it's possible to arrange for a particular callback chain to work differently. The cb_handle callback chain gives each callback function in the chain a chance to try processing data. If the callback is successful then none of the remaining callback functions in the chain will execute.
When a callback function is called it is passed a dictionary that contains the information in the HTTP request, the information from the configuration file, and any data that may exist in PyBlosxom at that point in time (usually a list of weblog entries). I'll be referring to this dictionary as the "args dictionary' in the rest of this document.
Here's a skeleton of a start callback function -- remember that all callbacks are prefixed with cb_.
def cb_start(args):
request = args['request'] # get the argument dictionary
config = request.getConfiguration() # config file information
http = request.getHttp() # HTTP header information
cgi_form = http['form'] # including any CGI form
data = request.getData() # the rest of the data
Basic Pipeline
Now we're ready to look at the various stages of the PyBlosxom pipeline. We're going to drill down through the various layers.
At the simplest level the execution of PyBlosxom is broken up into an initialization section and a "main" section. We'll skip over the initialization for the moment, since it is really only needed for entryparser usage, which we'll cover later on.
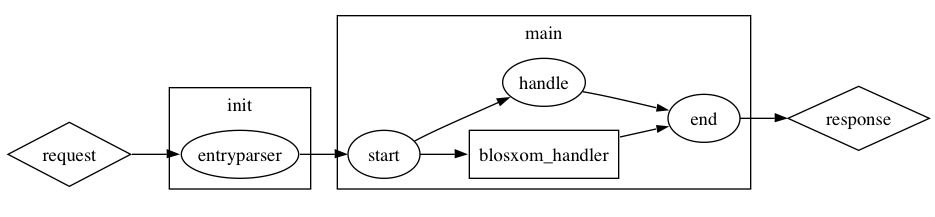
(In the diagrams I've omitted the cb_ prefix on the names of all the callbacks.)
The main section calls the cb_start callback, which is where you would perform any global initialization in your plugin if you needed that initialization to happen before any real work got done in the pipeline.
Next PyBlosxom will call any cb_handle callbacks. If a cb_handle callback is successful, PyBlosxom will jump to the end of its processing, calling any cb_end callbacks before it returns an HTTP response. (Note that the HTTP request is processed by the cb_handle callback in this case). If the cb_handle callback fails or there are no cb_handle callbacks registered, then processing passes to the blosxom handler, which does its job and then exits via cb_end.
The cb_handle callback provides a way to bypass the Blosxom handler in case you need to do a different kind of processing. Currently this is used to implement XML-RPC handling in PyBlosxom, since XML-RPC handling consumes and produces completely different input and output from regular PyBlosxom processing.
Blosxom handling
The blosxom_handler is a combination of a series of setup callbacks followed by a renderer that is actually responsible for producing the output.

The first of the setup callbacks, cb_renderer, is used to select a renderer to be used. At the moment, the core distribution contains a a Blosxom compatible renderer and a debugging renderer. People have expressed interest in building renderers based on other templating engines, such as Cheetah.
Now we come to the first callback function that actually does something with the HTTP request. The cb_pathinfo callback is charged with looking at the information in the request and modifying the data part of the plugin args dictionary with information about the type of entry being requested:
- 'bl_type' - the type ('dir' or 'file')
- 'pi_bl' - the HTTP PATH_INFO header
- 'pi_yr' - the yar
- 'pi_mo' - the month, either as a 2 digit number or 3 letter string
- 'pi_da' - the day as a 2 digit number
- 'root_datadir' - the full path to the entry folder in the filesystem
- 'flavour - the flavour of output requested
After cb_pathinfo has identified the entry being requested (and its type), the cb_filelist callback is used to generate a list of entries. The entries will all be instances of pyblosxom.entries.base.EntryBase, and will be stored in the data dictionary under the key 'entry_list'. In the default PyBlosxom configuration, these entries are actually instances of pyblosxom.entries.fileentry.FileEntry that represent weblog entries stored in the filesystem according to the Blosxom family rules. In particular, instances of FileEntry have the mtime (modified time) of the file for each entry, which is used to sort the entries in reverse chronological order for a typical weblog presentation. By providing your own cb_filelist callback, you could provide entries using some other storage mechanism, at least in theory. Currently PyBlosxom doesn't support storing entries in other storage mechanisms, though it's something we are looking into fixing in the future.
After the list of entries has been generated, it will be sent to the renderer to be formatted for output. Before this happens, there are two callbacks that can be used to alter that data that will be rendered.
The cb_prepare callback is a general-purpose callback that should be used to modify the data before the rendering phase. This can include injecting or filtering out entries, or modifying the data in specific entries. Another common thing to do in cb_prepare is to create new variables that can be accessed from the renderer, in order to provide some additional information. You can even use cb_prepare to handle HTTP POST requests, which is what the comments plugin does.
Just before rendering, the cb_logrequest callback is called. This is mostly used to log information to a file. To that end, it expects an entry in the argument dictionary whose key is filename. It also expects an argument entry keyed by return_code. This is why there is a separate callback (you ought to be able to do lots of logging type functionality using cb_prepare). The internal pathway through the PyBlosxom core is slightly different from that of cb_prepare, in order to obtain the return_code for cb_logrequest.
Rendering
By default, PyBlosxom uses a renderer that is based on the Blosxom template language. The renderer allows a template writer to insert variables into their weblog templates. At rendering time, the renderer replaces the variables with their actual values -- that's the meaning of 'render' in the context of PyBlosxom.
The Blosxoms combine several distinct templates in order to create a page in a weblog:
- head - the content of this template is inserted before any entries are rendered.
- date_head - the content of this templete in inserted at the start of a new day (the output is sorted chronologically).
- story - the content of this template is inserted once for each entry to be rendered.
- date_foot - the content of this templete in inserted at the end of a day (the output is sorted chronologically).
- foot - the content of this template is appended after all entries have been rendered.

The Blosxom renderer also has callback functions that you can provide in order to override behavior. The callbacks are named after the templates they are associated. They are all executed right before the template is rendered. There is also a callback that isn't associated with a template, cb_story_end that is called after the store template is rendered. Also, these callbacks are passed different arguments. They are passed a dictionary that contains all the variables that the renderer will use for template rendering.
- cb_head - before the head template is rendered.
- cb_date_head - before the date_head template is rendered.
- cb_story - before the story template is rendered.
- cb_story_end - the story template is rendered.
- cb_date_foot - before the date_foot template is rendered.
- cb_foot - before the foot template is rendered.
Entry Parsers
During PyBlosxom initialization there a call to the cb_entryparser callback. The cb_entryparser callback returns a dict whose keys are filename extensions and whose entries are functions uses to parse entry files whose extension is the key. This allows the user to use different formatting languages to write weblog posts. PyBlosxom includes entryparsers that can deal with ReStructuredText and Textile formats, as well as Python source code.
The blosxom_entry_parser (the default) parses entry files with extensions of '.txt'. The first line of a file will be the title of the entry, and the rest of the file will be the body of the entry. The body will be substituted directly in to the blosxom templates, and can contain HTML.
Entry parsers also support their own plugin mechanism. There are two callbacks, cb_preformat and cb_postformat that can be called before and after the entry parser has done whatever parsing it does. cb_preformat and cb_postformat must return a dict that contains entries for the 'title' and story keys. The dict can have more entries that just these two. PyBlosxom includes preformatters for allowing wiki words and replacing linebreaks with <br /> or <p>.
XML-RPC Subsystem
The XML-RPC subsystem is the last of the major PyBlosxom subsystems that we need to cover. It is interesting because it is implemented entirely via the plugin system - in fact it's contained entirely in the contributed plugins distribution. What we want is a way for PyBlosxom to handle requests made via XML-RPC. Initially, this is because we want to support some of the popular XML-RPC based blog authoring API's, such as the Blogger and Metaweblog API's. But we'd also like to make it possible for plugins (like the pingback handler for the comments plugin) to offer some of their services via XML-RPC, which means that we cannot hardwire the set of functions that are processed by the XML-RPC system.
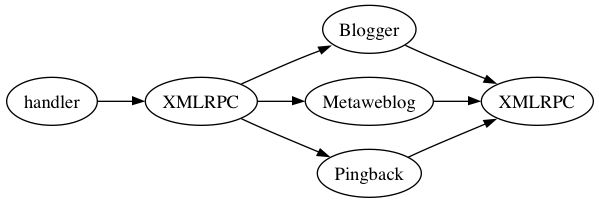
The XML-RPC system consists of a PyBlosxom plugin that acts as a dispatcher for all XML-RPC services. This plugin, named xmlrpc, is wired in via PyBlosxom's cb_handle callback, since we want it to process any HTTP request that contains an XML-RPC request. Recall that cb_handle bypasses the regular blosxom_handler flow through the PyBlosxom engine. xmlrpc also takes care of authenticating XML-RPC requests. The plugin takes care of dispatching XML-RPC requests by using a dispatch table stored in the plugin's args dictionary. The table is a Python dictionary that is accessed via the 'methods' key.
Every plugin that wants to offer its services via XML-RPC needs to provide a cb_xml_rpc_register function. This function must update the 'methods' dictionary with entries the map the XML-RPC method names to functions in the plugin's module. XML-RPC plugins may use any of the other PyBlosxom callback methods as well.
Example
Now let's take a look at a small plugin. This is my w3cdate plugin that creates a variable that contains the date in the 'time_tuple' variable in the ISO8601 format used by many W3C specifications, the Dublin Core extensions for RSS, and Atom.
import sys, time
def verify_installation(request):
# No configuration parameters
return 1
def cb_story(args):
entry = args['entry']
time_tuple = entry['timetuple']
try:
import datetime
import US
dt = datetime.datetime.fromtimestamp(entry['mtime'], US.Pacific)
entry['w3cdate'] = dt.isoformat()
except ImportError:
pass
try:
import xml.utils.iso8601
tzoffset = time.timezone
# if is_dst flag set, adjust for daylight savings time
if time_tuple[8] == 1:
tzoffset = time.altzone
entry['w3cdate'] = xml.utils.iso8601.tostring(time.mktime(time_tuple),tzoffset)
except ImportError:
pass
The verify_installation function is part of PyBlosxom's installation system. Your plugin should check to make sure that all the entries that it needs in the configuration dictionary are present.
The plugin uses the cb_story callback in the Blosxom renderer, so it has direct access to the dictionary of variables used by the renderer. The only trick here is that it uses some modules that aren't part of all Python installs (US, and xml.utils.iso8601), so we have to try to import the modules. If we can't import the modules then we do nothing. Otherwise the variable dictionary is augmented with the new entry, which can then be used by any flavor of the story template.
Future Plans
There are a number of areas where we are working to enhance PyBlosxom.
We have ongoing work to improve our support for environments besides CGI scripts. We have done some work on both WSGI and Twisted, which will appear when PyBlosxom 1.2 is released.
There is some support for static rendering in PyBlosxom, but it could be improved. We are also looking at various caching schemes in order to improve the performance of dynamically generate weblogs.
Over the years there has been a lot of interest expressed in trying an alternate templating engine as a PyBlosxom renderer. Cheetah is the engine that is most commonly cited, but any other would be welcome as well. This is an area where an interested party could make a new contribution.
A number of users have asked us to improve our internationalization support, so we are looking at ways to do the right thing.
On the plugin front, there has been a lot of activity around the comments plugin, which also supports Trackback and Pingback. There is quite a bit of interest in spam reduction techniques such as picture based challenges and comment moderation.
I hope that one day the Atom Working Group will complete work on a weblog authoring API. When that happens, we will need to build a PyBlosxom plugin to support that API. This is another area where someone could make a great contribution. If they were willing to get involved early, there is the opportunity to participate in work on the Atom API itself.
Conclusions
I would like to thank all of my fellow PyBlosxom contributors for their work on PyBlosxom. Working on PyBlosxom was my introduction to programming in Python, and I am using PyBlosxom to run my weblog (with over 1200 posts) today. Special thanks to Wari Wahab for kicking the whole thing off, and to Will Guaraldi and Bill Mill for their extensive comments on this paper.
You can find out more about PyBlosxom at the PyBlosxom web site.
The PyBlosxom community hangs out on the PyBlosxom Mailing Lists, and has a Planet style weblog aggregator at PlanetPyBlosxom
