Roundup Issue Tracker - PyCon 2005 Presentation
| Author: | Richard Jones |
|---|---|
| Date: | 2005/03/16 |
Roundup
- What is Roundup?
Roundup is a generic issue tracker -- it is a bug tracker, help-desk trouble ticket system, conference paper publication system.
It's designed for "knowledge workers" - people who deal with information that needs to be tracked in some way. This includes system administrators, software developers, sales teams, and so on.
- Why Roundup?
- most flexible and sanely designed issue tracker
- damn beautiful software.
- clear web and email interfaces ... pleasure to use
- has made me look like a hero/wizard for our customer-support team
- melded it to our needs in a remarkably short time.
- it's like Bugzilla without the six years of training
- or RT without that MySQL rubbish.
- 2000 to 2005
Roundup was designed by Ka-Ping Yee and submitted to the Software Carpentry competition back in 2000. He won the "track" class.
Software Carpentry then kinda fizzled out. Other people like me have taken up the challenge though - see SCCons (make-like tool).
Roundup's core still looks a lot like Ping's design. There's a lot added though: multiple backends, new HTML templating, some new database types, stored queries, and so on.
In March, 2005, we're up to stable release 0.8.2. That's 8 major feature releases.
Over the lifespan of the project there's been around 75 contributors - people with CVS access or just writing patches.
- What's it made of?
- Python
- Roundup's written entirely in Python with no required external dependencies, meaning you just need python to run it. It's usable as a set of Python modules - the core database layer may be used in other programs if you like.
- Web standards
- It uses valid HTML4, XHTML (or XML, though then you get to define what "valid" means), CSS in the web interface.
- Email interface
- The email interface speaks SMTP, POP, IMAP and Unix mailboxes (in and out).
- Databases
- It can use sqlite, metakit, mysql or postgresql if you want to. Files are stored on the filesystem.
- Why's it cool?
- Simple web interface
- The web interface is easy to use, and presents useful information up-front. Having said that, you can totally change the web interface if you really want to - it's fully templated and extensible.
- Powerful email interface
- Have a mini mailing list for each issue. Manipulate issues through email.
- Flexible schema and behaviours
- The only required class is the users list. Other than that, you can add and remove as you need. Additional automatic behaviours can be fired before and after any changes to the database.
- Trivial to install
- Requires no third-party software - just Python, which is installed everywhere. A tracker may be upgraded to use a faster backend when required - sqlite, metakit, mysql and postgresql are supported.
Issue Tracker
- Track...
We can track all manner of things. We can assign any properties we wish to them - status, title, priorities, etc. Each tracker may be customised to cater to suit site requirements.
- Bugs
- Well, bugs are just a kind of priority. Having said that, the classic Roundup tracker has three levels of bug: "critical", "urgent" and "bug". Of course, features may also be classified "critical" or "urgent" - if something's critical, it really doesn't matter whether it's a bug or feature.
- Features
- Features are also a kind of priority. There's two levels of feature in the classic tracker: "feature" and "wish". As mentioned before - if you don't like these priorities, you can set them to whatever you like. Or you can remove "priority" as a property and have "type" and "urgency" as separate properties.
- User Feedback
- May be accepted anonymously, or the submitters may be signed up to the tracker automatically with configurable permissions. The classic tracker does the latter by default.
- Milestones
- An easy extension to the classic tracker is to add "project" or "milestone" properties, assigned to each issue. You may then report on issue status by project or milestone. If you add in milestone dependencies, expected issue duration estimates and some simple code to plan the issue resolution order, you've got a simple project management tool. Someone has written code to display issues as a Gantt chart.
- Conference Papers
- So now we add in a bunch of extra properties to the base "issue" class to capture author name, conference registration id, etc. We add in properties on file uploads too, to indicate "draft", "referee", "final" and "typeset". Now you've got a collaborative system in which to manage the process of publishing refereed conference papers.
- Wiki Pages
- Add in a simple formatter to the web interface, and you've got a wiki engine.
- Software Overview
Roundup has many layers, starting from the user interface, going down through the tracker logic, the hyperdatabase and resting on the storage layer.
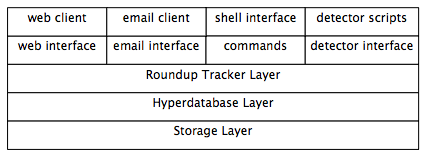
Simple to use
- User Interface Overview
Roundup has a number of user interfaces - all geared towards different styles of interaction with issues in the tracker.
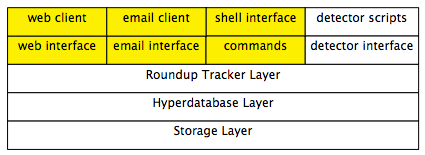
- Web
- Primary interface. Easiest to go in and manage various details about issues, and to search them. Has editing, searching (with saved queries) and a flexible templating and action system (more about this in a bit).
- Issues may be submitted by email. Change notes are sent out via email to selected users. Responses coming back in via email are attached to issues.
- Shell
- Useful for one-off, quick changes. Is a way to shell script Roundup.
- Python programs
- Use Roundup as a python library. Write scripts to generate reports, do general maintenance or perform random queries.
Web interface
- Issue Index Page
First screen shows issues, sorted by activity, grouped by priority.
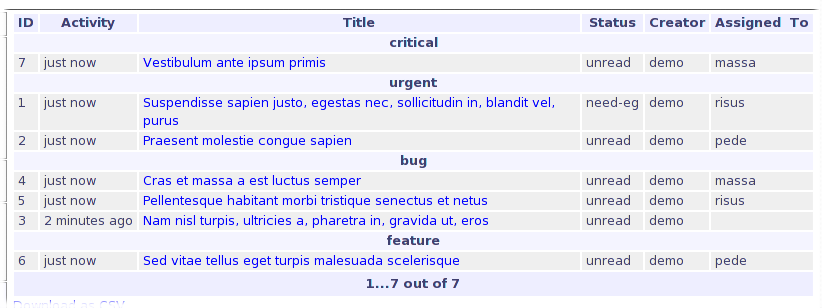
Reinforces one of Ping's primary goals - that the first page you see in the tracker should immediately provide useful information (by default, you see issues grouped by priority, ordered by last activity date).
- Issue Edit / Display Page
Issue page shows details form at top, notes field, file attachments, messages spool and finally the journal at the bottom.
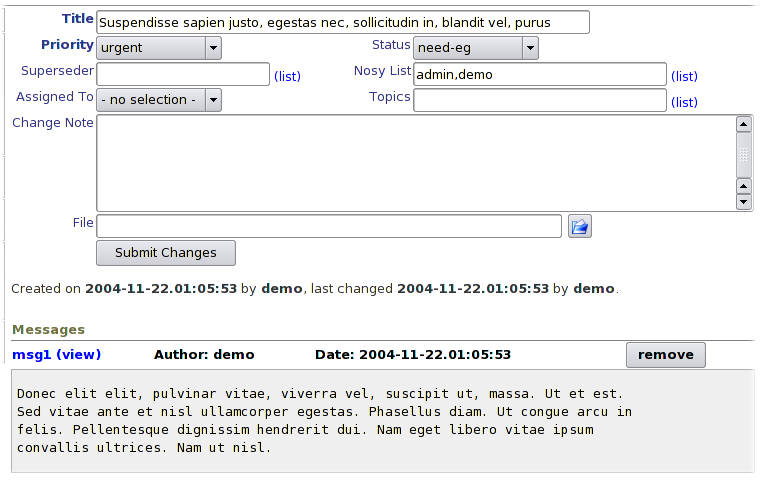
- Templated, Extendable
Fully editable interfaces either as HTML or XHTML with CSS making things pretty. We even have one user who converted it to frames. Another to XML.
You can extend the web interface with new pages, new actions, new templating functions. Possible (already implemented) alterations include wizards, parent/meta bug displays, wikis as mentioned before, ...
Flexible User Access
- Cookie Sessions
- Users have cookie-based sessions, if your particular interface needs them.
- Controlled Access
- May be set up to require login, and may also only allow admin users to register people.
- Register new users
- With optional verification via email.
- Or Apache basic auth
- If Apache does authentication of the user request and sets the REMOTE_USER environment variable, we can use it. Or we can do basic auth if we get an HTTP_AUTHORIZATION header.
- i18n
- Russian, German and French translations done. Dutch, Malaysian and Spanish are on the way. Interface handles unicode, no sweat. Smart-quotes "work".
- CGI, mod_python or stand-alone web server
- Lots of ways to run it. Zope too. The bundled stand-alone web server, roundup-server, is the easiest and most popular.
- Searching
- Lots of options for filtering issues, including date ranges.
- Useful content-type handling & filenames
- Download URLs always include the filename originally supplied to Roundup, so "Save As..." works as users expect, not some "download.php" silliness.
E-mail interface
Email comes into Roundup. How do we handle it? We start with...
- Subject line magic
We use the subject line to identify outgoing and incoming messages.
- [issue] The widget's frobulated
- New issue (no id) created with the title set to the subject.
- Re: [issue123] The widget's frobulated
- Response to issue 123.
- ... [priority=bug, assignedto=joe]
- We can set properties on issues by appending commands to the subject line in incoming messages.
- Out of the blue?
- Subject lines with no special markers will be handled as sanely as we can. If it looks like a response (ie. starts with 'Re:' or similar) then we try to match the subject line against existing issue titles. If there's no match, we create a new database item of a configurable class (default is a new issue).
- Sender Identification
- Users with multiple addresses
- Users with many email addresses are handled.
- Unknown sender?
- We can auto-register unknown users, with a configurable role assignment. This means support requests from unknown users may result in them being configured to have less permissions (say only able to view their own issues).
- Message content
- Message Body
- Incoming email must have a plain text part. This is used to form a new message attached to the issue. If the plain text part is accompanied by an HTML alternative part, the alternative is discarded.
- Attachments
- E-mail attachments are handled sanely. Sane handling of content-type and content-encoding.
- Message-Id
- Incoming message ids are retained. In-Reply-To set on outgoing messages if appropriate. We hope to make more use of these one day.
- Nosy list
- Each issue has a "nosy list" which forms a mini mailing list. A standard detector watches the "messages" property on issues. When a new message is added, the detector sends it to all the users on the "nosy" list for the issue that are not already on the "recipients" (loaded initially from the To: and Cc: list of the incoming message) list of the message. Those users are then appended to the "recipients" property on the message, so multiple copies of a message are never sent to the same user.
- Lots of setup options
- Pipe (sendmail-like delivery alias)
- POP
- IMAP
- Unix mailbox.
- TLS, APOP, IMAPS
Command-line
- roundup-admin
- Interactively manage roundup databases, scripted using standard shell scripting.
- "import roundup"
- API may also be used by other Python programs
- Samples
- Report open issues, add issue, dump schema to "dot" file, synchronise user database with another source and scan multiple IMAP mailboxes.
Your Tracker
- A Roundup Tracker
A Roundup tracker is represented on-disk by...
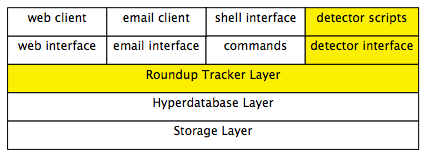
The components of a tracker follow.
- Configuration files
- Each tracker has bunch of configuration files controlling basic Roundup properties -- the database schema.py, config.ini.
- Database
- The contents of the tracker are stored in the database directory, usually called db. It can be put elsewhere (another disk, on ugh NFS). The MySQL and Postgresql backends store some data wherever their databases reside.
- HTML interface
- The pages that form the web interface reside in the tracker's html directory. Also in there are support files like images, CSS and javascript static files.
- Customisations
- Other customisations come in the form of python modules which are kept in the detectors (automatic behaviours) or and extensions (new templating functions and web actions) directories.
- Templated
Trackers are created by using a template. A tracker itself may be used as a template for another tracker. A tracker template consists of the databse schema, some default configuration file, detectors, extensions, HTML templates and support files.
Yes this means you could distribute your tracker template for others to use. In reality, this isn't done because you'll find that your tracker is quite specifically tailored to your business needs. In our case, our work tracker has regular issues (with some changes), conference papers and sales leads, all in the one place. Not likely to be useful anywhere else.
Hyperdatabase
- The Database
The hyperdatabase is flexible data store holding configurable data in records which we call items.
The hyperdatabase is implemented on top of a storage layer - anydbm, sqlite, metakit, mysql or postgresql. Anydbm comes with python, so we work out of the box.
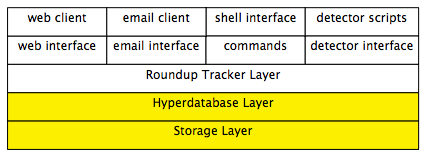
Text files are stored on-disk and are therefore accessible for shell commands.
- Database Schema
Defined in a tracker's schema.py file, tells us the shape of the tracker's hyperdb. You can make any change you want to your tracker's schema - except removing the users class. You can have multiple types of issues tracker in the one tracker (eg. development, conference papers and sales leads)
- Classes of data
- Here we define the chunks of stuff we're talking about - issues, users, messages, priorities, ...
- Properties on Classes
- Here we define the specific properties we're capturing for those chunks of stuff - title, priority, nosy list, message content, ...
- Property Types
Properties may be of a number of types.
- String
- Some text
- Number
- Either integer or floating-point.
- Boolean
- Yes / No, True / False, 1 / 0
- Date
- Captured in the user's timezone, stored as UTC, represented in the viewing user's timezone. Date arithmetic included.
- Interval
- Any number of intervals may be used, and we may represent intervals in a nice, user-friendly manner such as "just now" or "1 hour ago".
- Link
- Links to some other item in the hyperdb. We use this for constrained fields such as properties. See also "assigned to".
- Multilink
- Links to a number of other items (of a particular class) in the hyperdb. Used for message spools, nosy lists, related issues, ...
- Full history
Full history of changes to issues with configurable verbosity. "create", "edit", "link" and "unlink" events. Also allows us to have auto-properties. When messages are added to an issue, their journal has a "link" entry added.

- Auto-properties
We also have a number of properties managed by the hyperdb.
Creation -- First journal record: when?
Creator -- First journal record: who?
Activity -- Last journal record: when?
Actor -- Last journal record: who?
- Automatic behaviours
Tracker detectors are automatic actions that fire when data in the hyperdb is changed.
Auditors fire before a change is made, for example:
- Block unwanted attachments in email,
- Prevent closure of issue with dependents, or
- Perform GPG verification.
Reactors fire after a change is made, for example:
- Close parent / meta issues,
- Email someone every issue create, or
- Send email to a selected users (eg. nosy list).
Permissions
- Permissions, Roles, Users
- Access is controlled through an extensible set of Permissions. Roles group together Permissions into logical groupings (ie. the Admin Role can do everything, the User Role can do some things, a "Guest User" Role could do less, etc). Users are assigned one or more Roles.
- View, Edit, Create
- Permission checks are performed manually by appropriate code (the web and email interfaces do this for you) during View, Create and Edit operations, but also for things like just looking at the Web interface.
- Classes, Properties, Code
- Permissions normally apply to classes of items. They may also apply to specific properties (eg. user email address View permissions might be restricted). Permissions may have code attached (eg. users can edit only their own user record)
- Searching
- Roundup includes a full-text index for searching which is available across all backends. Work is currently underway to allow use of higher- performance indexing systems like Postgresql's TSearch2. Use of that indexer would be optional, since not all Postgres installations have it.
Documented
- Installation
- Fairly complete docs covering Unix, Windows, OSX. Variations of install covering different mail gateway configurations and web interfaces, and advice about how to select an appropriate backend.
- Upgrading
- If something changes in a feature release, I give clear instructions how to upgrade. Happens less these days. 0.8 will be a big change, but actually not too difficult to upgrade to.
- Maintenance
- Docs for sysadmins. Includes information about how to backup, what's installed when you install Roundup, how to upgrade...
- Users
- Docs for users. Runs through the basics of the user interface, both email and web.
- Customisation
- Docs for anyone who wants to change their tracker. Includes information about how to change a tracker's schema, automatic actions, the web interface and has a list of example modifications at the end.
Simple to install
A guiding principle, based on my experience with other tracker software, is to make Roundup as trivial as possible to get going.
- Quick
- Installation takes about 30 minutes. Trying out the bundled demo (which may be used as a starting point for your tracker) takes less than a minute.
- No fuss
- Python (2.3+) is enough to get you going.
- Upgradeable
- Easy to set up higher-performance storage backends like sqlite and postgres.
- "python demo.py"
- Unpack the source and run. Figures a port to run on, initialises a "classic" template tracker, configures nosy reactor off and launches the web interface.
Community
- Mailing List
- A users mailing list exists for people who need help. This list is archived. To subscribe to the list, visit the Roundup web page, http://roundup.sf.net/
- Contributors
- Contributions are always welcome. Most features are implemented by someone (usually me) who needs the feature, or thinks it'll be fun to implement. Patches are good. Working directly in CVS is encouraged.
- Wiki
- Link formatting, time logging, "grab bag" issues, pie chart status summaries, message spool as mbox, ... and, of course, wiki spam
The Future
- The Near Future, That Is
Since 0.8 was just released, development now mostly goes into maintenance mode, until I've recharged enough to launch into the next features. Some things I've got planned for the next release:
- challenge-response for email registration,
- retaining rego OTKs to avoid double-load problems,
- refactoring the hyperdb to allow multiple backends in one tracker...
- Longer-Term
- 1.0 is probably close. I don't know exactly what it will consist of though, which is a problem. I'm not that fussed though.
- Python Project
- The Python project is looking to switch to Roundup for its issue tracking.